Yesterday I attended the Tampa IIBA’s chapter meeting to see the presentation given by Kara Sundar, titled Communicating With Leaders: Increase Your Productivity and Influence. The presentation was very effective and based on materials from the book Change Intelligence by Barbara Trautlein.
Ms. Sundar described how people with different viewpoints contribute to and shape projects in different ways, based on their individual concerns, roles, and outlooks. Three primary axes are defined, as shown in the first figure below. The three axes are defined as “Head,” “Heart,” and “Hands,” which you can otherwise think of as thinking, feeling, and doing.
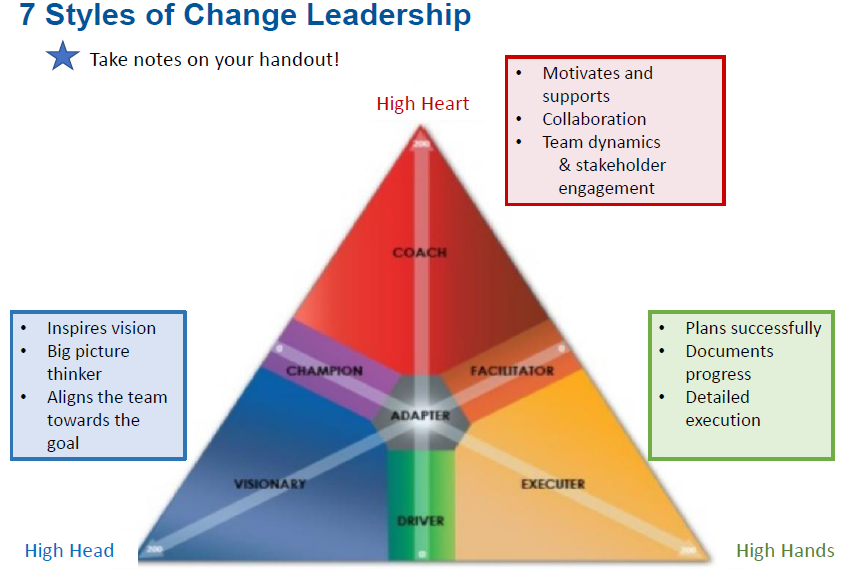
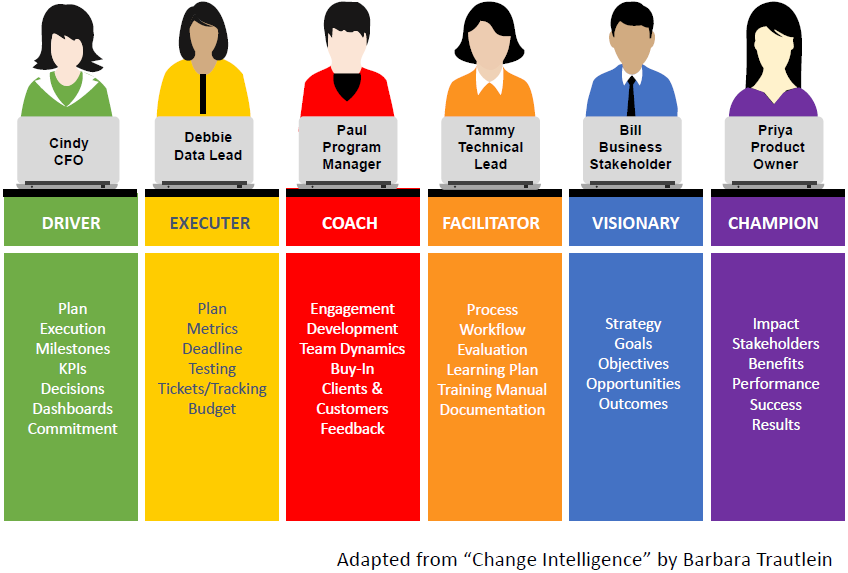
Six roles are then defined with respect to these axes as follows. Primary concerns of each role are listed in the bullets and in the second image below.
- Visionary: Centered on high end of head axis
- Strategy, Goals, Objectives, Opportunities, Outcomes
- Champion: Between high ends of head and heart axes
- Impact, Stakeholders, Benefits, Performance, Success, Results
- Coach: Centered on high end of heart axis
- Engagement, Development, Team Dynamics, Buy-In, Clients & Customers, Feedback
- Facilitator: Between high ends of heart and hands axes
- Process, Workflow, Evaluation, Learning Plan, Training Material, Documentation
- Executer: Centered on high end of hands axis
- Plan, Metrics, Deadline, Testing, Tickets/Tracking, Budget
- Driver: Between high ends of hands and head axes
- Plan, Execution, Milestones, KPIs, Decisions, Dashboards, Commitment
- Adapter: Centered around the origin of the intersection of all aces
- Essentially a hybrid of all the other roles
The context of the presentation was that different kinds of people approach activities in different ways. Understanding the different possibilities can provide some insight into why your co-workers, customers, and stakeholders might see things differently than you do, and also suggest guidance for bridging those gaps. In that regard it serves sort of the same function as Myers-Briggs Personality Indicators which, whether you like them or not, at least give some appreciation that people can be different and how they might be understood and approached. (This book describes potential MBTI applications in the workplace.) No such representation is going to be perfect, but each can serve as a useful point of departure for thinking about things.
Barbara Trautlein included a radar chart of the prevalence of the outlooks in the general population, which she probably derived from survey data she collected. It showed the occurrence from most to least prevalent to be (roughly) Champion (22%), Coach (20%), Visionary (17%), Adapter (15%), Executer (11%), Driver (8%), and Facilitator (7%). Graphically, this skews up and left on the triangular plot. One might be tempted to observe that more people seem to care about how the work gets done than about actually doing it, but, when Ms. Sundar tried to survey the room, the BA practitioners there skewed hard to the lower right. (I’ve done so much of all these I’ve become an adapter, but I definitely skewed towards the practitioner-doer end of things when I started out.)
I generally like frameworks that try to classify concepts in a useful way, but it took me a while to let this sink in. My original impression was that this classification was the flip side of the Nine SDLC Cross-Functional Areas breakdown defined by Kim Hardy that I wrote about a couple of years ago. Ms. Hardy defines nine team roles in terms of realizing different functional parts of a solution (Business Value, User Experience, Process Performance, Development Process, System Value, System Integrity, Implementation, Application Architecture, and Technical Architecture). These are more the whats of a project, which is contrasted with the schema Ms. Sundar described, which defines the hows. There’s a hair of overlap, but I think the formulations are trying to get at different things. Both, of course, are useful and thought-provoking.
This made me think about my own analytic and procedural framework, which defines a series of iterative phases that guide progress through a project or engagement. My phases are Planning, Intended Use, Assumptions/Capabilities/Risks, Conceptual Model, Data Sources, Requirements, Design, Implementation, Test, and Acceptance. (This can be shortened to Intended Use, Conceptual Model, Requirements, Design, Implementation, and Test.) This framework tries to incorporates the hows and the whats through time. It’s not a stretch to map the Change Intelligence or SDLC Cross-Functional roles to the phases in my framework.
In fact, let’s try it. Not only am I going to try to map the Change Intelligence and SDLC roles to the phases in my framework, I’m going to map yet another set of defined roles to it, based on the roles I’ve served in over the years.
- Bob’s Framework Phase: Planning
- CI Roles: Driver, Executer, Coach, Visionary, Champion
- SDLC Roles: Business Value, System Value, Application Architecture
- Bob’s Roles: Systems Analyst, Project/Program Manager, Full Life Cycle Engineer
- Bob’s Framework Phase: Intended Use
- CI Roles: Facilitator, Visionary, Champion
- SDLC Roles: Business Value, System Value, Application Architecture, Technical Architecture
- Bob’s Roles: Systems Analyst, Project/Program Manager, Full Life Cycle Engineer
- Bob’s Framework Phase: Assumptions/Risks
- CI Roles: Driver, Visionary, Champion
- SDLC Roles: Business Value, System Value, Application Architecture
- Bob’s Roles: Systems Analyst, Project/Program Manager, Full Life Cycle Engineer
- Bob’s Framework Phase: Conceptual Model
- CI Roles: Coach, Facilitator, Champion
- SDLC Roles: Business Value, System Value, Application Architecture
- Bob’s Roles: Systems Analyst, Product Owner, Discovery Lead
- Bob’s Framework Phase: Data Sources
- CI Roles: Driver, Executor, Facilitator, Champion
- SDLC Roles: Business Value, User Experience, System Value, System Integrity, Application Architecture, Technical Architecture
- Bob’s Roles: Systems Analyst, Product Owner, Data Collector, Data Analyst
- Bob’s Framework Phase: Requirements
- CI Roles: Driver, Executer, Coach, Facilitator
- SDLC Roles: Business Value, User Experience, Process Performance, System Value, System Integrity, Application Architecture, Technical Architecture
- Bob’s Roles: Systems Analyst, System Architect, Software Engineer, Product Owner, Project/Program Manager, Full Life Cycle Engineer
- Bob’s Framework Phase: Design
- CI Roles: Executor, Coach, Facilitator
- SDLC Roles: Business Value, User Experience, Process Performance, Development Process, System Value, System Integrity, Implementation, Application Architecture, Technical Architecture
- Bob’s Roles: Systems Analyst, System Architect, Software Engineer, Product Owner, Project/Program Manager, Full Life Cycle Engineer
- Bob’s Framework Phase: Implementation
- CI Roles: Driver, Executer, Coach, Facilitator
- SDLC Roles: User Experience, Process Performance, Development Process, System Integrity, Implementation, Application Architecture, Technical Architecture
- Bob’s Roles: Systems Analyst, System Architect, Software Engineer, Product Owner, Project/Program Manager, Full Life Cycle Engineer
- Bob’s Framework Phase: Test
- CI Roles: Driver, Executer, Coach, Facilitator
- SDLC Roles: User Experience, Process Performance, Development Process, System Integrity, Implementation
- Bob’s Roles: Systems Analyst, System Architect, Software Engineer, Product Owner, Project/Program Manager, Full Life Cycle Engineer
- Bob’s Framework Phase: Acceptance
- CI Roles: Driver, Executer, Coach, Facilitator, Visionary, Champion
- SDLC Roles: Business Value, User Experience, Process Performance, System Value, System Integrity, Application Architecture, Technical Architecture
- Bob’s Roles: Systems Analyst, System Architect, Product Owner, Project/Program Manager, Full Life Cycle Engineer
This is not the cleanest of exercises as you can see, which is an indication that every role and outlook applies across a variety of activities. Some of the activities I listed on my Roles page are so general or otherwise apply out of context that I didn’t include them here. They are, Tech Lead, Simulation Engineer, Operations Research Analyst, Control Systems Engineer, Field Engineer, and Process Improvement Specialist. The Independent VV&A activity from my Portfolio page indicates that I should also define a role of Test and V&V Agent, since I’ve served in that role in many projects and contexts, even if I haven’t done it in a specialized, standalone capacity in an organization. The Program Manager role should probably be applied only to the beginning and ending phases of individual efforts, leaving Project Managers to handle the details during each one.
Other roles, like ScrumMaster and Scrum Developer can overlap the above roles and phases in different ways. Other functional specialties haven’t been included in these discussions, either. They include roles like Database Analyst/Developer, Graphic Artist, and UI/UX Designer, and perhaps even Business Analyst (I see a systems analyst as being more general). The number of roles that can be defined are potentially endless, which probably contributes to some of the confusion which exists in the practice of business analysis. To that end I’ve been working on a Unified Theory of Business Analysis, which I’ll be writing about in the coming days.