
I finally finished the Udemy course on Jira and Confluence. As I watched each section of the course I thought about how the capabilities of the two products can be used to represent Requirements Traceability Matrices, and furthermore how they could be used to do so for my project framework.
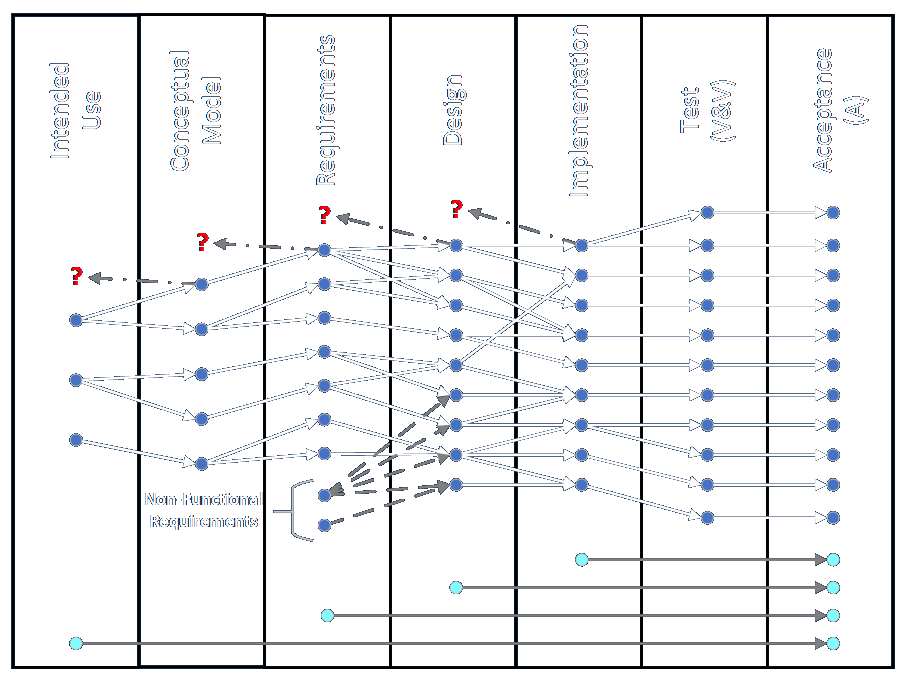
My framework includes the idea of linking one-to-many and many-to-one between columns going from left to right (beginning of project to end) and, as I’ve thought about it in detail over the last week-plus, I see that it might also include the idea of linking items in non-adjacent (non-successive) columns. Might. I’ll be clarifying that going forward. Anyway, the framework is best represented using a graph database, which is a bit out of the ordinary, as I’ll explain.
Since the ultimate representation I have in mind is complicated, I’ll describe a simple representation and slowly add complications until the end goal is reached.
Start Off Doing It By Hand
Let’s start with a fairly simple project and describe how I would manage it manually. Since I’ve usually done this in combination with building simulations of some kind we’ll build on that concept as well.
The intended uses describe how the solution will be used to solve identified business problems. Imagine there’s only a single item to keep it simple. Give it a code of A-1.
The items in the conceptual model are identified though a process of discovery and data collection. These define the As-Is state of a system. Label these items B-1 through B-n. Each is linked to intended use item A-1. These can be stored in a document, a spreadsheet, or a database, but picture the items written in a document.
The items in the requirements address how to represent and how to control each conceptual model item. These define a path to the To-Be state in an abstract way. Label these items C-1 through C-n. Each item is linked to one of the conceptual model (B-) items, such that every B- item is linked to a requirement. Those describe the functional requirements of the solution. Non-functional requirements are listed with labels C-n+1 through C-x. They do not have to link back to conceptual model items. Imagine these items are written in a document.
The items in the design describe the proposed ways in which the solution will be implemented. These represent the To-Be state in a concrete way. The items must include the details of the implementation process. Label them D-1 through D-x. Each item is linked to one of the requirements (C-) items, such that every C- item is linked to a design item. Imagine these items in a document as well.
The implementation items are tracked as they are assigned and worked on. They should be labeled E-1 through E-x and each should be lined to a design (D-) item such that all of the design items link to implementation items. These items can be listed in a document.
The test items are labeled F-1 through F-x and are linked to implementation (E-) items such that all E- items are linked to test items. These items can be written in a document.
The acceptance items are labeled G-1 through G-x and are linked to implementation (F-) items such that all F- items are linked to acceptance items. These items can also be listed in a document.

That description may be tedious and repetitive but it gives us a place to start.
The first wrinkle we might introduce is to include all of the items in a single document in an outline or tabular form. It gets unwieldy as the number of items grows, so another idea would be to include the items in a spreadsheet, where we can combine the features of an outline and columns, and where the rows can be viewed easily even as they grow wider.
Test items are interesting because there are so many different forms of them. There are many types of automated and manual tests and there are a number of software systems that track the items and generate reports. Such systems can be used to supplement the written forms of the previous items. Such systems usually support labels that fit any scheme you like. Specialized tests that aren’t tracked by automated systems can be tracked in written form. The more subjective tests that rely on expert judgment are most likely to be tracked in writing.
The virtue of keeping everything in writing like this is that intended uses, conceptual model items, requirements, and designs can be maintained as separate documents and possibly be managed by separate teams. The labeling and cross-linking have to be performed manually by one or more people who have a solid understanding of the entire work flow.
Enter Jira (and Confluence)
Here’s where we get to Jira and Confluence. The simplest way I can think of to integrate Jira into the RTM process is to use it to store the status of implementation items only. This means that the items in columns A through D, or the intended use, conceptual model, requirement, and design items, can stay in there separate documents. The design items can be written in such a way that they define the work to be done by the implementation agents. They can be written as user stories, epics, tasks, or sub-tasks.
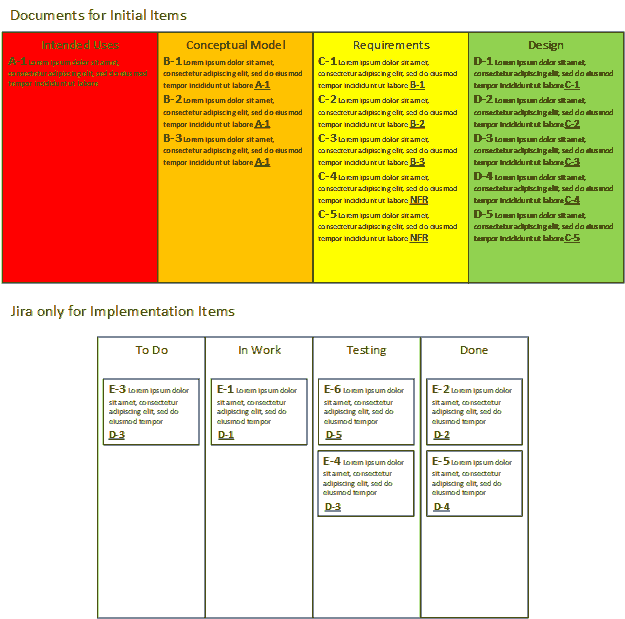
These items can be given custom workflows that move items through different kinds of evaluations. They follow all the rules for writing effective descriptions, including definitions of done, and so on. This works well for different layers of testing. For example, a software item’s definition of done may include requirements for integrated tests. There might be a code review step followed by a manual test step. A custom workflow could handle many situations where multiple test (F-) items are mapped to each implementation (E-) item. They could handle the parallel definitions of tests in a written document of test items by walking the implementation items through a serial test process. Subjective tests could be run as a separate step for some items.
Why not use Jira for tracking items from phases before implementation? I can think of a few reasons.
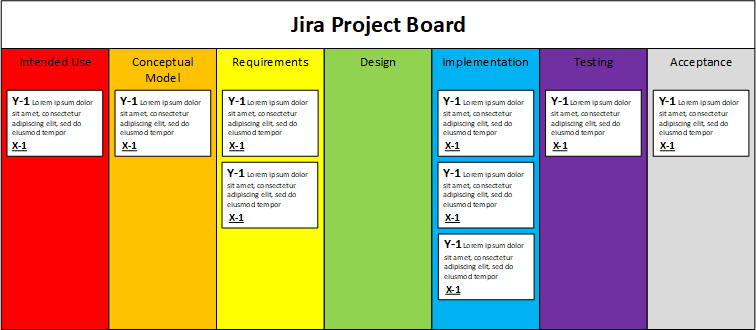
- The items walk through all phases and cannot therefore be conveniently viewed in the context of each phase. That is, it’s not super easy to see all of the items together in their context of, say, the conceptual model. This objection can be overcome by including a custom field with the relevant text, and then using JQL (Jira Query Language) functions to list and sort the information in those fields as desired.
- It’s difficult to capture all of the one-to-many relationships that are possible advancing through the phases left to right. This can be overcome somewhat for testing as described above but it breaks down trying to span more than two of the other phases (e.g., concept-to-requirement-to-design). Capturing many-to-one relationships wouldn’t be a treat, either.
- Each item in each phase may require a lot of documentation in terms of text, data, history, discussion, graphics, and so on, so trying to maintain all of that through multiple phases seems like it could get out of control in a big hurry.
- Most of the material I’ve seen on Jira is in the context of handling action items. Implementation and test items are actions to take, but it’s harder to think of earlier phase items in that way. Up until the implementation phase the items serve more as background for the work to be done. I suppose you could create implementation items like, “do discovery” and “collect data” and “write requirements,” but those items don’t yield a traceable list of individual items unless the context is understood.
The latter concern leads to a major issue that needs to be discussed.
Waterfall vs. Agile
It might sound like my framework, with its need to do a lot of upfront elicitation, conceptualizing, and requirements gathering, forces you into more of a Waterfall mode. Agile, by contrast, promises to let you begin doing meaningful work almost right away, starting from a small core of obvious functionality and progressively elaborating to a complete, thorough, nuanced solution.
Waterfall, at its worst, involves a huge amount of planning with the idea that most of the analysis is performed at the beginning, so that the implementers can go off and do their own thing and all of the pieces will automagically come together at the end. We know from experience that that way lies madness. Plenty of projects have failed because the pieces do not come together at the end and even if they do, the lack of interaction with and feedback from the customers means that the developed system might not meet the customers’ needs very well — or at all. This can happen even if the initial customer engagement is very good, because customers might not know what they even want to ask for in the beginning, and lack of ongoing interaction denies them the opportunity to leverage their specialized experience to identify opportunities as the work and refinement progresses.
Agile techniques in general, and Scrum techniques in particular, are intended to maintain customer engagement on the one hand, and ensure the implementation team always has something running and it continually revisiting and working out integration and release issues. Agile and Scrum at their worst, however, assume that you don’t need to do much upfront planning at all and you can just start building stuff willy-nilly and hammer it into shape over time. We used to call that cowboy coding and it was seen as a bad thing back in the day. Putting a shiny gloss of Scrum in it doesn’t fundamentally change the fact that such an approach is broken. (It also means that querying would-be hires about Scrum trivia items to gauge their knowledge entirely misses the point of how work actually gets done and how problems get solved. Asking about the philosophical purpose and application of Scrum make sense, btw.)
I could go on and on about how Agile and Scrum have been misused and misunderstood but I’ll keep this brief. The truth is that the approaches are more reasonably viewed on a continuum. It isn’t all or nothing one way or the other. You’re crazy if you don’t do some upfront work and planning, and you’re also crazy if you don’t start building something before too much time has gone by. What are some factors that change how you skew your approach in on direction?
- The scope and scale of the envisioned solution: Smaller efforts will generally require less planning and setup.
- How well the problem is understood: If the analysis and implementation teams already understand the situation well they will generally require less planning.
- The novelty of the problem: If the problem is recognizable then the amount of planning will be reduced. If it takes a long time to identify the true problem then much or even most of the work will involve upfront analysis.
- The novelty of the solution: If a team is adapting an existing solution to a new problem then the amount of upfront will will be reduced. The team can start modifying and applying parts of the solution as discovery and data collection proceed. If a novel solution is called for it’s better to wait for more information.
- The planned future uses of the solution: If the solution is going to be used for a long time, either as a one-off or as the basis of a modular, flexible framework (i.e., a tool) that can be applied over and over, it’s a good idea to devote more effort to analysis, planning, and setup. If the effort is to keep an existing system afloat for a while longer, a quick implementation will do, if it’s appropriate. Note that it’s possible to develop a flexible tool or framework over numerous engagements, slowly developing and automating parts of it as consistent, repeating elements are identified. This may be necessitated by funding limitations. Building and using tools imposes an overhead.
- The quality of the desired solution: Every effort is constrained by the iron triangle of cost, quality, and time, where quality may be expressed in terms of features, performance, robustness, maintainability, and so on. Put a different way, you can have it fast, cheap, or good: pick two. At the extreme you could have it really fast, really cheap, or really good: pick one! The space shuttle had to be really good (and they still lost two of them), but it was really not fast and really not cheap.
There’s some overlap here but I’m sure you can recall time when you faced the same decisions.
In simulation in particular you pretty much have to understand what you’re going to simulate before you do it, so there might be a lot of upfront work to do the discovery, data collection, and planning to understand a new system and adapt a solution. However, if you already have a solution you merely need to adapt to a new situation, you can jump in and start customizing to the novelties almost as soon as they’re identified. I’ve worked at both ends of this spectrum and everywhere in between.
Roughly speaking, if you have to do a lot of upfront work the effort will tend toward Waterfall, though within that you can still use Agile and Scrum techniques to do the implementation, guided by the customer’s impression of what provides the most business value first and the implementer’s impression of what is technically needed first.
If you have reasonably well-understood problems and solutions, as in handling ongoing bug fixing and feature requests for an existing system, and where you are operating mostly in a reactive mode, the effort will tend toward a Kanban style.
For efforts that are somewhere in the middle, where there is a balance between planning and execution or discovery and implementation, the preferred m.o. would tend toward Scrum. Interestingly, teams sometimes use Kanban approaches in this situation, not because there are being strictly reactive, but because they are using Kanban as an effort-metering approach for a team of a fixed size. In those cases I’m thinking that the cost or scope or time would have to be flexible, and this approach might not work for a firm, fixed price contract with an external client.
People’s impression of management techniques, specifically regarding Waterfall and Agile/Scrum/Kanban can vary strongly based on their own experience. They may tend to think that the way they’ve done it is the only or best way it should be done. They may also regard the body of knowledge surrounding Scrum as being very rigid and important to follow closely, although I view the whole thing more as a guideline or a collection of techniques rather than holy writ. I pretty much figure if you’re treating Scrum procedures as holy writ you’re doing it wrong. That said, I am not saying that an appreciation of the context and application of the generalized ideas is not helpful or necessary.
I’ll also observe that the context of Scrum and Kanban is pretty limited. If I look through the training materials from the certification classes I took a while back I can argue that a significant amount of material in those booklets is general management, professional, and computer science stuff that doesn’t have much if anything to do with Scrum or Agile. In that regard the whole movement is a bit of a fraud, or at the least an overblown solution looking for a problem. This is why the initial champions of the technique have more or less moved on.
As for me, I’m fond of noting that I’ve been doing Agile since before Agile had a name, even if I hadn’t been doing explicit Scrum. I always started with discovery and data collection to build a conceptual model of the system to be simulated or improved. I always identified a flexible architecture that would solve the problems in a general way. I always built a small functional core that got something up and running quickly that was then expanded until the full solution was realized. I always worked with people at all levels of customer organizations to get ongoing feedback on my understanding and their satisfaction of the solutions’ operation, look and feel, accuracy, functionality, and fitness for purpose.

I finally note that, especially for the product owner role, the ability to perform relevant subject matter analysis, apply industry expertise and business judgment, the ability to communicate with all manner of specialists from users to managers to line operators to technical teams, and the ability to create and understand solutions are all far more important than any specific knowledge of Agile, Scrum, Jira, or any related technique or tool. Relative to understanding and being able to work with people and technology to solve problems, Agile and Scrum are trivial. This is especially true is other strong Scrum practitioners are present.
For example, the product owner role will sometimes be filled by a senior manager of a customer organization or internal competency, while a ScrumMaster will be a member of a vendor organization or a different internal competency. In these cases the product owner might be an expert in the business needs and be able to work with knowledgeable members of the solution team to groom the backlog in terms of business value, but that individual might not know a thing about the details of the proposed technical solution, how to do DevOps, how to write code, how to run a Scrum ceremony, or whatever. Such an individual would be guided by the ScrumMaster to get up to speed on the Scrum process and by specialists on the technical team(s) to work on the solution elements themselves. Like I said, every organization will treat these functions differently. Ha ha, I guess I should do a survey of the expected duties and capabilities of the expected Scrum roles are to illustrate the wide range of different approaches that are taken. It was highly illuminating when I did this for business analysts!