
Now that we’ve described how to sense error states and something about how to record logging information on systems running multiple processes, we’ll go into some deeper aspects of these activities. We’ll first discuss storing information so errors can be recovered from and reconstructed. We’ll then discuss errors from nested calls in multi-process systems.
Recovering From Errors Without Losing Information and Events
We’ve described how communications work between processes on a single machine and across multiple machines. If an original message is not successfully sent or received for any reason, the operation of the receiving or downstream process will be compromised. If no other related events occur in the downstream process, then the action downstream action will not be carried out. If the message is passed in support of some other downstream action that does occur, however, then the downstream action will be carried out with missing information (that might, for example, require the use of manually entered or default values in the place of what wasn’t received). An interesting instance of the latter case is manufacturing systems where a physical workpiece may move from one station to another while the informational messages are not forwarded along with them. This may mean that the workpiece in the downstream station will have to be processed without identifying information, processing instructions, and so on.
There are a few ways to overcome this situation:
- Multiple retries: This involves re-sending the message from an upstream process to a downstream process until a successful receipt (and completion?) is received by the upstream process. This operation fails when the upstream process itself fails. It may also be limited if new messages must be sent from an upstream process to a downstream process before the previous message is successfully sent.
- Queueing requests: This involves storing the messages sent downstream so repeated attempts can be made to get them all handled. Storing in a volatile queue (e.g., in memory) may fail if the upstream process fails. Storing in a non-volatile queue (e.g., on disk) is more robust. The use of queues may also be limited if the order in which messages are sent is important, though including timestamp information may overcome those limits.
- Pushing vs. Pulling: The upstream process can queue and/or retry sending the messages downstream until they all get handled. The downstream system can also fetch current and missed messages from the upstream system. It’s up the the pushing or pulling system to keep track of which actions or messages have been successfully handled and which must still be dealt with.
There may be special considerations depending on the nature of the system being designed. Some systems are send-only be nature. This may be a function of the communication protocol itself or just a facet of the system’s functional design.
In time-sensitive systems some information or actions may “age out.” This means they might not be able to be used in any meaningful context as events are happening, but keeping the information around may be useful for reconstructing events after the fact. This may be done by hand or in some automated way by functions that continually sweep for unprocessed items that may be correlated with known events.
For example, an upstream process may forward a message to a downstream process in conjunction with a physical workpiece. The message is normally received by the downstream system ahead of the physical workpiece so that it may be associated with the workpiece when it is received by the downstream system. If the message isn’t received before the physical piece the downstream process may assign a temporary ID and default processing values to the piece. If the downstream process receives the associated message while the physical piece is still being worked on in the downstream process then it can be properly associated and the correct instructions have a better chance of being carried out. The operating logs of the downstream process can also be edited or appended as needed. It the downstream process receives the associated message after the physical piece has left, then all the downstream system can do is log the information, and possibly pass it down to the next downstream process, in hopes that it will eventually catch up with the physical piece.
Another interesting case arises when the communication (or message- or control-passing) process fails on the return trip, after all of the desired actions were successfully completed downstream. Those downstream actions might include permanent side-effects like the writing of database entries and construction of complex, volatile data structures. The queuing/retry mechanisms have to be smart enough to detect whether the desired operations aren’t repeated if they have actually been completed.
A system will ideally be robust enough to ensure that no data or events ever get lost, and that they are all handled exactly the right number of times without duplication. Database systems that adhere to the ACID model have these qualities.
Properly Dealing With Nested Errors
System that pass messages or control through nested levels of functionality and then receive responses in return need a message mechanism that clearly indicates what went right or wrong. More to the point, since the happy path functionality is most likely to work reasonably well, particular care must be taken to communicate a complete contextual description of any errors encountered.
Consider the following function:
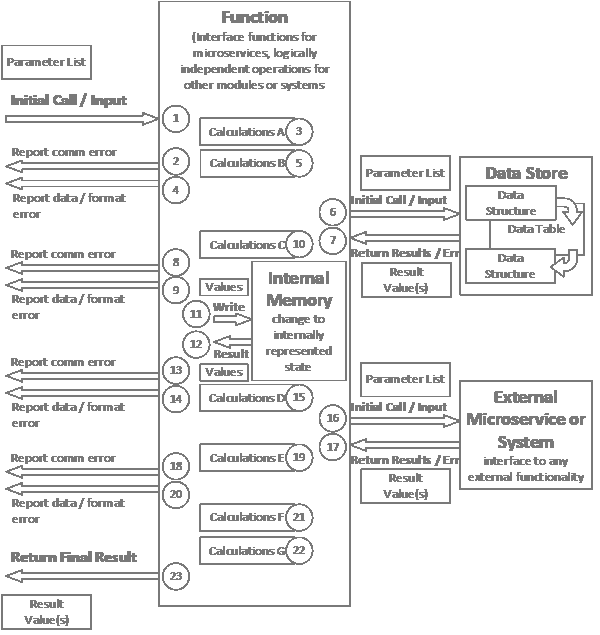
A properly constructed function would return errors from every identifiable point of failure in detail and unidentifiable failure in general. (This drawing should also be expanded to include reporting on calculation and other internal errors.) This generally isn’t difficult in the inline code over which the function has control, but what happens if control is passed to a nested function of some kind? And what if that function is every bit as complex as the calling function? In that case the error that should be returned should include information identifying the point in the calling function, with a unique error code and/or text description (how verbose you want to be depends on the system), and within that should be embedded the same information returned from the called function. Doing this gives a form of stack trace for errors (this level of detail generally isn’t needed for successfully traversed happy paths) and a very, very clear understanding of what went wrong, where, and why. If the relevant processes can each perform their own logging they should also do so, particularly if the different bits of functionality reside on different machines, as would be the case in a microservices architecture, but scanning error logs across different systems can be problematic. Being able to record errors at a higher level makes understanding process flows a little more tractable and could save a whole lot of forensic reconstruction of the crime.
Another form of nesting is internal operations that deal with multiple items, whether in arrays or some in other kind of grouped structure. This is especially important if separate, complex, brittle, nested operations are to be performed on each, and where each can either complete or fail to complete with completely different return conditions (and associated error codes and messages). In this case the calling function should return information describing the outcome of processing for each element (especially those that returned errors), so only those items can be queued and/or retried as needed. This can get very complicated if that group of items is processed at several different steps in the calling function, and different items can return different errors not only within a single operation, but across multiple operations. That said, once an item generates an error at an early step, it probably shouldn’t continue to be part of the group being processed at a later step. It should instead be queued and retried at some level of nested functionality.
Further Considerations
One more way to clear things up is to break larger functions down into smaller ones where possible. There are arguments for keeping a series of operations in a single function if they make sense logically and in the context of the framework being used, but there are arguments for clarity, simplicity, separation of concerns, modularity, and understandability as well. Whatever choice you make, know that you’re making it and do it on purpose.
If it feels like we’re imposing a lot of overhead to do error checking, monitoring, reporting, and so on, consider the kind of system we might be building. In a tightly controlled simulation system used for analysis, where calculation speed is the most important consideration, the level of monitoring and so on can be greatly reduced if it is known that the system is properly configured. In a production business or manufacturing system, however, the main considerations are going to be robustness, security, and customer service. Execution speed is far less likely to be the overriding consideration. In that case the efforts taken to avoid loss of data and events is the main goal of the system’s operation.