A while ago someone asked me how I’d go about making two processes communicate. My answer was to figure out what data needed to be communicated, what communication type was to be used, what protocol was to be used, and how control was to be arranged. I then stated that I would document everything that was required in each of those areas, including test cases, and review said documentation with all relevant parties to ensure they agreed with what was documented (e.g., a customer might acknowledge that their requirements were properly understood) and understood what was documented (e.g., a development team might ask questions about anything that seemed unclear, ask for support in carrying out any part of the process they might not understand or have tools for, and possibly offer suggestions for better or different ways to do it).
I then began to give examples of the many different ways I’ve accomplished such tasks throughout my career. For some reason my explanation did not make headway with this individual. The individual was either looking for a specific example (e.g., the get coordinates from postal address function in the Google Earth API using JSON, as if that or something like it was the only acceptable answer) or simply wasn’t considering the question broadly enough.
To that end, and with the goal of providing additional descriptive material which can be linked from my online resume or home page, I offer the following details about the numerous ways I’ve solved this type of communication problem in the past.
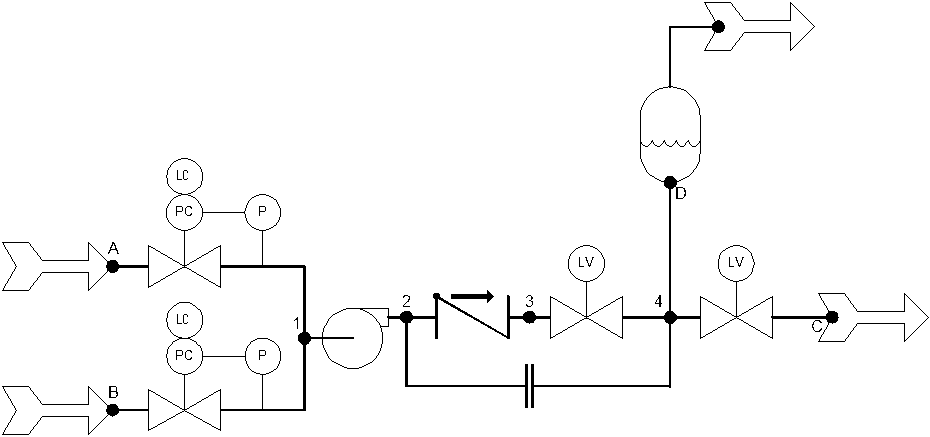
Serial (RS-232, RS-485)
I wrote control systems for a maker of reheat furnaces for the metals industry from 1994 to 2000. I wrote supervisory control systems using model predictive simulation in high-level languages (FORTRAN, C/C++, and Pascal/Delphi) for DEC (VAX and Alpha) and PC hardware. These systems employed a number of communication mechanisms to exchange information with other plant business and control systems. Our presence in the metals industry and our ability led to our being acquired by Inductotherm when our company’s founder, Francis Bricmont, decided to retire in 1996.
One of the tasks Inductotherm wanted us to take over explicitly was to write a new, PC-based version of control software for their electrical induction melting furnaces. While that was being done they also needed someone to take over support of their existing induction furnace control product, called MeltMinder 100, which was a PC-based DOS program which used serial communications to interact with several types of devices. It was written in Microsoft Visual C++ and since I was the only guy who regularly wrote high-level language software the task fell to me. I helped another team of new hires design the replacement product, MeltMinder 200, which they (inexplicably) chose to implement in Microsoft Visual Basic, but I had to handle all the mod requests and troubleshooting for the 100 version for the four years I remained with the company.
The original design of Inductotherm’s hardware employed serial communications between all devices. The Meltminder software had to talk to a number of different components to read data from sensors and write data to control various events.
- Inductotherm VIP (Variable Induction Power) supplies: These devices provided finely controlled power to the induction furnaces.
- Omega D1000/2000: These small devices in hexagonal packages (we colloquially referred to them as “hockey pucks”) each provided a combination of analog and digital inputs and outputs that could be used to communicate with a range of external devices including thermocouples, tilt meters, scales, actuators, alarms, and so on. One unit provided the required I/O for each furnace.
- 2-line dot matrix displays: These devices showed one or two lines of up to about 32 characters of text and provided a low-level shop floor interface to the system and were also used to show the weight of material in a furnace.
- Spectrometer interface: Some systems incorporated spectrometer readings which were used to define the chemistry (in terms of the percentage of each element present) of the current material in the furnace. The MeltMinder software could then do a linear optimization to figure out what combination of materials to add (each of which had its own, known chemistry) to achieve the target melt chemistry with the minimum amount of additions by weight.
The reliance on serial communications imposed certain limitations and complexities on MeltMinder systems. DOS-based PCs could only support a limited number of serial ports and this necessarily limited the number of furnaces which could be controlled. The Windows NT PCs could support more serial ports, and they ended up with serial connectors that were muti-headed monstrosities. As I review Inductotherm’s offerings now it seems that they’ve updated the MeltMinder software to a version 300, and I know they also divested themselves of Bricmont and took their control software development back in-house.
American Auto-Matrix makes products for the building control industry (primarily HVAC but they also integrate access control and other systems). Their unit controls, area controllers, and PC software communicate using a number of different protocols with one of the chief ones being serial. This is effective for low bandwidth communications over long distances with few wires. TCP/IP, BACnet MS/TP, ModBus, StatBus, and proprietary communications were also used.
I worked on several modifications of the PC-based driver software. It handled TCP/IP messages across Ethernet networks (to area controllers and other PCs) and could be connected directly to serial devices for configuration and monitoring. The communication driver software was implemented as a .DLL in Microsoft Visual C++.
Serial communications were carried out as a series of messages in two possible protocols, publicly defined and supported by American Auto-Matrix. The PUP and PHP protocols defined the meaning of each byte in each possible message. Each protocol included 12-20 possible message types in different configurations and the software included a cyclic redundancy check (CRC) for each message sent and recieved.
- PUP and PHP protocols between lines of unit and area controller devices.
I took a course called Real-Time Computing in the Laboratory during my junior year at Carnegie Mellon University. Our software was written in assembly language for sample development boards based on the Motorola 68000 microprocessor (that powered the original Macintosh computers). I was fascinated to learn the internal structure and working of processor chips and remember being impressed at how streamlined the Motorola chips seemed to be compared to the extant Intel (8088, 8086, 8087) chips then available.
That aside, we did a number of projects exploring low-level computing and different kinds of communications with external devices. Serial communications were used to talk to a couple of different things. I don’t remember what they all were but I remember learning about interrupt request lines and how electrical signals from external devices could trigger jumps to interrupt code that would save the current program state on the stack, read the input and process it, then restore the original program state by popping the relevant information back off the stack.
One project I do remember involved trying to get an HO scale model train (i.e., a single, small locomotive) to go through the gap between the blades of a rotating windmill (i.e., a small electric motor and a cardboard disc with chunks cut out).
- Train sensor: I want to remember that his was a physical contact of some sort that sensed when the train was present in a given location. It would read as being continually on as long as some part of the train was on or over that point of the track.
- Windmill blade sensor: This was an emitter-detector pair that generated signals when the signal was broken and when it was reestablished.
- Power supply: We controlled the power output to the track by managing its duty cycle. This meant that we continually turned the power supply on and off and the frequency and proportion of time turned on determined the total power supplied to the track.
I felt this class was invaluable for teaching me about how high-level software works under the hood. We also used our knowledge of assembly language code to learn a little bit about how compilers worked, but that’s a different discussion. Suffice it to say that some of the assembler outputs were very difficult to relate back to the high-level loop, conditional, and indirect referencing code that generated it.
Parallel
The Real-Time Computing in the Laboratory class also included a project where we used a parallel port to interact with an external device. The device was an aluminum box with a row of 16 LEDs and 16 toggle switches. We started with just reading the switch positions and writing the LED on/off state but ultimately created a little game that turned on LEDs on either end of the row and turned off a shifting set of LEDs in the middle of the row. The goal of the game was for the player to continually turn on a second switch and turn off the previous switch in order to move the player LED so it didn’t touch the LEDs on either end as they shifted to and fro. This was akin to trying to drive a “car” down a twisty “road” without driving off of it.
- Box with 16 LEDs and 16 switches.
TCP/IP messaging
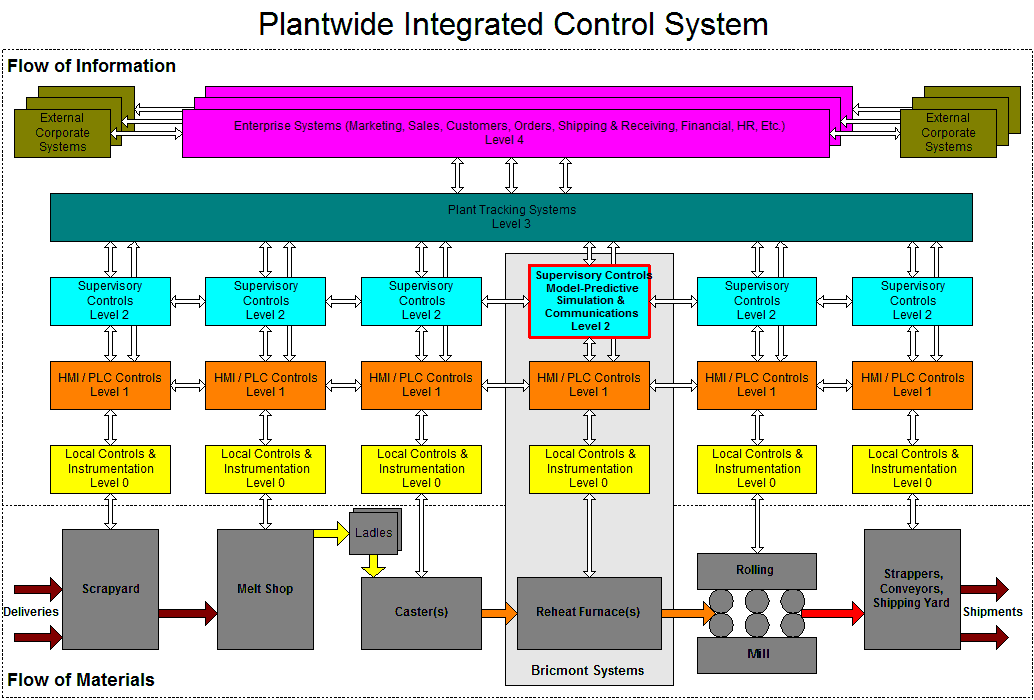
My main job at Bricmont was writing Level 2 supervisory code that controlled reheat furnaces using a model-predictive control scheme. The system had to read inputs from several external systems and write outputs to several other external systems. The concept is shown in the figure below.
Some of the communications were accomplished by sending TCP/IP messages directly across the Ethernet network. Doing this required defining the meaning of each byte in the message and the size of the message. On my end I always sent and received the message as a block with a defined number of bytes. I had to pack the header bytes with the information required by the TCP/IP protocol itself and the body bytes with the information agreed to by the author of the connected system. I wrote systems directly employing this method in Borland C++ Builder.
When moving large blocks of data I often like to define variant records (also known as free unions). Sometimes the entire record can be variant and sometimes only the latter part of the record is like that. This method allows the programmer to refer to a second of memory using different handles. Individual structure variables can be read and written as needed and the entire block can be processed as a unit for speed and simplicity. Different languages make this more or less easy to do. Fortunately, FORTRAN, Pascal/Delphi, and C/C++ all make it easy. It is more difficult to do in languages like Java, but the same effects can be achieved using objects and polymorphism.
- TCP/IP messaging to remote PC for external status display.
The PC software and area controllers made by American Auto-Matrix also employed TCP/IP messaging. It was written in Microsoft Visual C++ as a .DLL and handled the sending and receiving of packets using an interrupt mechanism. This software required population of the header and body parts at a lower level than I had to do at Bricmont, but was not otherwise a problem.
- Driver DLL for Auto-Pilot PC interface software: This was used to communicate with area controllers and other PC stations.
I used this method to initiate the communication process for a simulation plug-in that was otherwise controlled via the HLA protocol, as described below
- Initiation mechanism for automated simulation evacuation plug-in: This was used as part of Lawrence Livermore’s ACATS System. The software was written in Microsoft visual C++ as a wrapper for a system largely written in SLX. I wrote the proof-of-concept demo using Borland C++ for the wrapper around SLX.
DECMessageQ:
This protocol is provided on DEC systems in various languages (I used both FORTRAN and C/C++) to enable communications between the Level 2 furnace systems built by our company and the Level 2 caster and rolling mill systems built by other companies (we worked with SMS systems a lot). We also used this method to exchange data with the plantwide Level 3 system.
- Caster Level 2 Systems: These messages were sent to the furnace control system whenever a slab was produced by the caster. We needed to know the dimensions, melt (which batch of molten steel, implying a particular chemistry and usually customer), ID (which individual slab or billet in each melt), weight, and other information about each piece as it entered the furnace.
- Rolling Mill Level 2 Systems: These messages were sent to the rolling mill whenever a slab or billet was discharged from the furnace. The caster needed to know the information sent by the caster plus things like average and location temperatures, furnace residence time, and discharge time.
- Plant Level 3 Systems:Some information was passed directly between Level 2 systems but some was passed via the Level 3 system. Other information was passed to the Level 3 system describing fuel consumption, delays, and special events.
High-Level Architecture (HLA)
HLA is a protocol used by distributed simulations to synchronize and control events in the system. A common use of this protocol is in military engagement simulations where trainees in hardware-in-the-loop simulators, sometimes separated by great distances, can participate in mass battles. The protocol specifies actions, locations, starts and stops, and so on. The protocol is pretty minimalist but the amount of information needed to describe events in detail might be both voluminous and complex. It is an exercise that necessarily carries a lot of overhead.
- One of the projects I managed at Regal Decision Systems was an evacuation plug-in for the ACATS system being managed by Lawrence Livermore National Labs. ACATS is a distributed simulation system that lets multiple users engage in a variety of interactions. Such engagements sometimes call for the movement of large numbers of entities (e.g., people or vehicles), but the overhead and expense of involving numerous individual users would be excessive. To that end we wrote an automated simulation of pedestrians evacuating a building. The system was initialized by forwarding a building layout defined as an IFC (Industry Foundation Classes, a BIM format) model, and then defining interior locations of building occupants. Our software then figured out where the evacuees could go and incrementally moved them toward efficient exits when given permission to do so. I wrote the initial demo code that showed how we could marry the HLA extension to the SLX programming language to do what we wanted. Interestingly, the process of initializing our system required some sort of messaging prior to initializing the HLA process, so I leveraged my previous experience to define and guide the implementation of a TCP/IP messaging process that kicked the process off. By the way, the Regal system was implemented in a combination of C++ and SLX on Windows XP while the ACATS system was implemented in C++ and other things running on Linux.
Memory Sharing
Many of the furnace control systems I wrote at Bricmont involved numerous processes all mapped to a common area of memory. The programs all had their own local data segments but an initial program allocated a memory structure on the heap that was tagged with the operating system in such a way that other programs are able to map to the same location. Since the same data structure definition is built into all of the programs that need to share data in this way they are able to read and write the same locations using the same names.
The various programs run in continuous loops at different rates. The programs that communicate with external systems run a bit more quickly than the fastest rate at which they would expect to need to send or receive messages. The model process runs as quickly as it can given the computing time it requires, plus a buffer to give other programs enough duty cycle to be sufficiently served and to allow decent response from the UI.
Each program writes a timestamp to a heartbeat variable on each cycle while a monitor program repeatedly checks to see whether too much time has elapsed since each program last updated the variable. If the heartbeat is not updated by any program, the monitor program can issue a command to terminate the offending process if it’s still running but hung, and then issue a command to restart the program. As a practical matter I was never aware of any program that ever caused a hang in this way.
Each process tended to read or write information in the shared memory block in a single bulk operation during each cycle. Before reading they each check against lock variables to ensure that nothing else is writing to a shared variable at the same time. If some other process is writing to that section of memory the reading program will briefly pause, then check again until it receives permission to read. The same process is followed by programs wanting to write to shared memory. They check against the requisite read flags and only perform their writes when they have permission. These locking mechanisms ensure that processes don’t exchange data that may be inconsistent, possibly containing data from partial reads or writes.
- DEC systems written in C/C++ and FORTRAN: Most DEC systems were installed to control tunnel furnace systems but the first one I did was for a walking beam furnace.
- PC-based systems written in Borland C++ Builder or Borland Delphi (Pascal): Systems written for all other kinds of furnaces were hosted on PCs as soon as I felt they were powerful enough to support the computational load required of them. Being able to switch to PCs and Windows/GUI-based development tools made the systems both far cheaper and much more informative and engaging for the users.
- Thermohydraulic models written in FORTRAN for nuclear power plant simulators on Gould/Encore SEL 32/8000-9000 series minicomputers: The SEL systems included four processors that all shared the same memory space. Different models and processes communicated using a common data map (the Data Pool) and the authors of different parts of the system had to work together to agree on what kind of interfaces they were going to arrange between the processes they wrote.
File Exchange
CSV, Binary, and XML files could be written to or read from local hard drives and drives that were mapped on remote systems so they were seen by the local OS as a local drive. Windows-based systems made this very simple to do at least beginning with Windows NT. Even better, the local hard drive could sometimes be configured as a RAM disk, so the code could treat the read and write processes like simple file operations but proceed as if communicating with RAM rather than a physical disk. Lock files were used in place of shared memory variables as describe above, but the process was the same. Lock files were written when the read or write operation proceeded on the transfer file, and then the lock files were erased. Other processes needing access to the transfer data file merely needed to check on the presence of a lock file to know whether to wait or proceed.
I believe that this process was only used on PC-based systems, but it may have been used on some DEC-based systems as well. The files could be written in any format, including .CSV, binary, or XML, but .CSV was the most common. Philosophically any file transferred between and used by multiple systems is a form of inter-process communication.
- Communications between Bricmont’s Level 1 and Level 2 systems often used this method.
- At one mill we wrote out fuel usage data to an external system that tracked energy usage in the plant. That company identified ways for the customer to save energy and was paid based on a percentage of the money the recommendations saved.
At Regal Decision Systems we wrote a system to optimize the evacuation of buildings in the presence of a detectable threat. The threat detection system sensed the presence of airborne chemicals, modified the settings of the HVAC system and certain internal doors, performed a predictive fluid simulation of the location and density of threat materials over time, and wrote the result file out to a shared disk location. The evacuation guidance system imported the threat information, mapped it to several hundred locations in the building, and used the information to specify a series of directions that should be followed by building occupants in order to escape the building in minimum time and with minimal exposure to the threat. The system then wrote another file out to the lighting system specifying the preferred direction of travel down every segment of corridor and indications of whether to pass through or pass by every relevant door. The calculated threat-over-time file could run to a gigabyte in size and was formatted as a .CSV file. The lighting solution file was small and also formatted as a .CSV.
- Evacuation Guidance System: communication between threat detector and evacuation optimizer
- Evacuation Guidance System: communication between evacuation optimizer and egress lighting system
Web APIs
XML/AJAX and JSON/AJAJ information can be passed over the web in languages like JavaScript and PHP. This is a standard method supported by numerous web systems. I wrote and successfully executed API calls of both types while completing a Web Developer’s course on Udemy in 2015.
- Google Earth location API: I completed exercises which used JavaScript.
- Twitter API: I completed exercises using PHP. Annoyingly, I needed to create a Twitter account to do so. I’ve always avoided Twitter, and I haven’t looked at it since.
Database Polling
Toward the end of my time at Bricmont our customers began asking up to perform inter-process communication by reading from and writing to database tables on remote systems. This changed neither the architecture nor the internal operation of our systems; we only had to interact using SQL operations rather than by exchanging files, TCP/IP packets, or other kinds of messages. We polled databases and checked against timestamps and lock records to see if there was anything new to read, and wrote when we needed to, after also checking against lock records.
Handling the passing of messages in this way allowed databases to be used as communication systems as well as historical archiving systems. I wrote archiving functions in my Level 2 systems that worked by writing to and reading from binary files. I’m sure my successors moved to purely database-driven methods not too long after that.
- Communications with plantwide Level 3 system: We implemented this on a system for a big walking beam furnace. We wrote the system in Borland C++. The remote databases we interacted with were by Oracle. We learned what we needed by taking a one-week Oracle training course, which covered far more information that we needed. We may also have communicated with caster and rolling mill systems in this manner, but I remember that the most substantive information was exchanged with the Level 3 system. We probably passed notification of charge and discharge events to the remote Level 2 systems, but the ID, melt, and dimensional information was received from and sent to the Level 3 database.
Screen Scraping
I describe how I used this process here.
Dynamic Data Exchange (DDE)
This older capability of some Microsoft products (e.g., Word and Excel) enabled processes to modify contents of documents and other data repositories (Wonderware apparently had this capability as well). The products had an API that allowed them to be manipulated as if a user was interacting with them directly. One example usage was that templates for form letters could be defined, including named fields, and external programs could then control the subject programs to open the desired template, populate the defined fields using dynamic data, and save or print the resulting document. The capability enabled control of both content and formatting.
- Generation of customized documents in FileNet WorkFlow systems: We arranged for automated creation and modification of different kinds of documents when we built document imaging systems as part of large-scale business process re-engineering efforts.
Processes can communicate in many different ways. I still feel that giving a general view of the steps to be taken is the correct way to begin, and that can be followed by examples. And if you want examples, this description should provide plenty.