
Having developed software for systems large and small, as well as performed every kind of software testing services known to man – I’ve been involved with most kinds of software testing. Here are the major details from my experience.
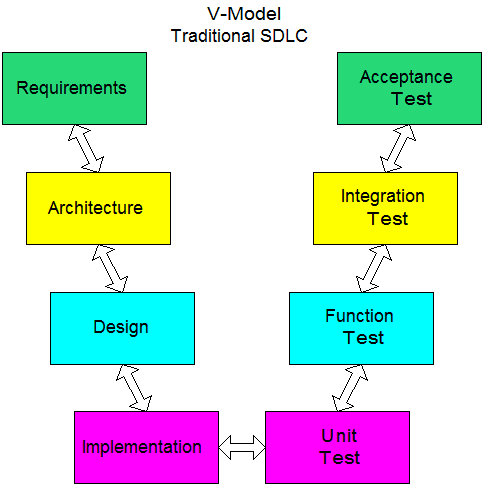
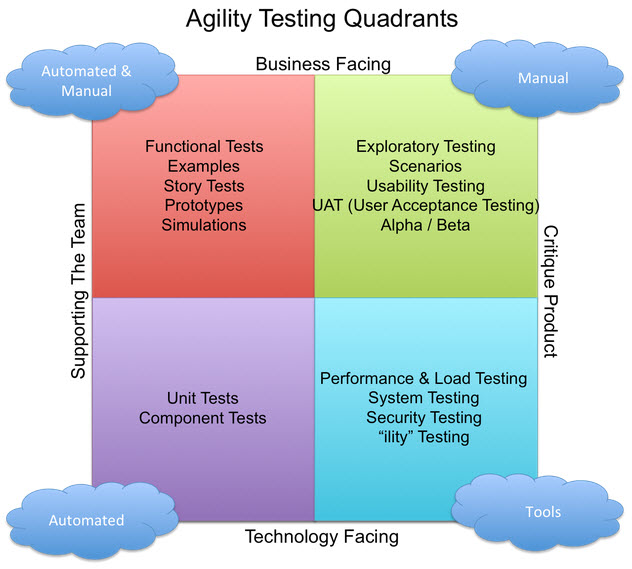
The traditional way of defining and conducting tests is shown in the V-Model, and the more recent Agile, Four-Quadrant concept of testing is shown below. While trying to classify the methods I’ve employed over the years I see it is difficult to place them neatly to one “box” or another in either model. The V-Model places integration testing halfway through the process while the Agile Quadrant model seems to place it near the “beginning”. However, the two models are really different temporally; the Agile Quadrant model suggests time more loosely than does the V-Model, but in the real world most tests are conducted cyclically anyway. Good developers didn’t need to learn Agile and Scrum formally to know enough to test, demonstrate, and seek feedback early and often. Therefore I will group my experiences in my own way.
Testing Local Code
This is all about getting your own code to work. As much as possible you want to not have to worry about interactions with external hardware or software. This is the most granular type of test. New capabilities that automate a lot of this process make it much simpler to find problems in code long thought to be stable as other parts of the code are added or modified.
- I’ve used JUnit in Java development. It enables Test-Driven Development by supporting the creation of tests prior to writing the code. They fail before the code is written and then, hopefully, pass after the code is written. These independent test functions can be as simple or complex as necessary, and streamline the kind of work that used to get done in other ways. They are generally intended to be small, numerous, and automated. These are mostly used to test local code but can be used to support integration tests as well.
- I learned a little about Mockito when I was qualifying for my CSD. This clever bit of subterfuge bypasses the behavior of the function actually called and produces the developer’s defined behavior (the mock) in its place. This allows code to run in a standalone mode when you don’t have access to connected systems, third-party libraries, or other functionality. I’ve generally thought about this kind of spoofing to be a higher form of testing, like functional or integration testing, but in this instance the intent is to support testing of the local code, not the interactions. One can also spoof these behaviors in less elegant ways. The real code can be commented out and the desired response can be dummied in, but then the developer has to remember to change the code before release. Conditional debugging statements can support the same behavior in a slightly more elegant way. Using mocks has the virtue of leaving what is hoped to be the final code in place in its final form and without the need for changing any switches.
- A lot of my development has been perfected through classic interactive debugging tools, beginning with Turbo Pascal (Version 4.0, I think). Most subsequent programming environments have supported this. That said, there are cases where this method cannot be used effectively, and more primitive methods have to be used instead. As Jeff Duntemann once observed, “An ounce of analysis is worth a pound of debugging.”
- In more primitive situations I’ve resorted to the classic method of embedding write statements in the code. Sometimes I’ve only needed to write out critical values in the area of the problem, but other times I’ve had to write out much more detailed information, including essentially a full stack trace. This method is also helpful in real-time or other interactive situations that would not operate with the potential delays inherent in interactive debugging.
- In rare cases I’ve used sound to provide runtime information. Power-On Self-Tests (POST Tests) for computer boards often do this.
- In many cases you can tell what’s going wrong simply by looking at the output, of which there are too many kinds to list.
- I’ve often developed small sections of code in isolation, and then integrated the whole into the larger project. This was always good for 3D graphics, communications widgets, matrix calculations, and automatically generated code. It was also useful for independently graphing the outputs of functions for material properties and random distributions. This may also be thought of as component testing.
- I wrote a simulation framework that allowed the developer to display any desired variable after any time step. In some ways the system behaved like a giant set of watch statements in an interactive debugger. The power plant simulators I worked on provided the capability that initially inspired my project. The tool I wrote also contained a number of graphic elements like multi-trace scrolling graphs, animated bar graphs, and other moving plots.
- The simulation framework allowed me to vary the states of external variables that were referenced by the model. This could be done in simple or complex ways. The simulation could be frozen and such a variable could be edited by hand, or the interface variable could be made to change automatically in a prescribed way (e.g., sine wave, random walk, programmed or random step change, and so on).

Integration Testing
Once you get all the pieces working you see if they can play nice together. This is applicable to testing systems that interact with the outside world, with other computer systems, with other software processes on the same machine, or with specialized services like databases.
- Many of the systems I worked on integrated multiple software processes on a single machine or a group of tightly coupled machines. The processes often communicated through a single block of shared memory. Testing these interactions meant ensuring they were all using the same definition of the shared memory space, ensuring that certain values were locked and unlocked as needed, that race conditions were avoided, and so on.
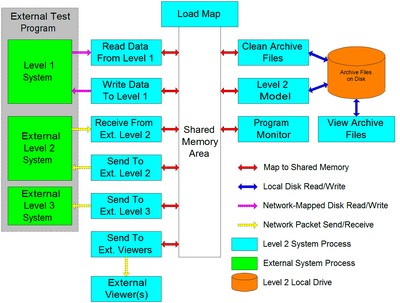
- In other cases my systems had to communicate with external computers. This was usually though high-level protocols like TCP/IP, FTP, DecMesageQ, and writing files to commonly-mapped disks (hard drives or RAM disks). The messages, protocols, addresses, and permissions all had to be verified. I was never able to do standalone testing on the DEC machines we used in steel mills but for PC-based systems I created my own test program that replicated the behavior of all external systems either exactly or nearly so. That way I could run and test my own programs unchanged and have them respond to every possible change in the external systems. I even made the external test program respond to the commands to change its parameters.
- Plantwide systems started to integrate database access as a means of interfacing higher-level systems. Rather than wait for a semaphore or other message the systems would actively poll a database on an interfacing system. The code would execute defined SQL scripts we developed to perform the same functions our earlier interfaces had, complete with locking and re-trying loops.
- Systems that interfaced closely with external hardware needed to be physically connected to it. I tested systems, programs, and drivers that interfaced to a broad assortment of hardware devices though RS-232 and RS-482 serial connections. Some of these involved publicly published general protocols while others were specific to individual devices. Some involved TCP/IP messages. In the case of a system meant to control induction melting furnaces the core system had to interact with a number of serial devices, some of which were themselves in communication with multiple sensors and controllers.
User Testing
This type of testing involves examining the way users interact with the system. This can be through hardware or software, though my concern was almost always with the software.
- I learned about Selenium while qualifying for my CSD. That seemed more robust than previous automated UI testing methods that involved macros that embedded mouse movements and actions.
- Most UI testing I’ve been involved with has been manual. That said, sometimes the users have gone off to do their own thing and sent back comments, while in other cases I sat with the users or managers and received their feedback directly. In many cases I was able to make the desired changes on the spot.
Business Acceptance Testing
These are higher-level tests meant to address business behaviors the customer cares about. They are conducted at the level of a user story, a business function, or some other “chunk” of functionality.
- As part of a team that performed an Independent VV&A on a major analytical system (a deterministic model meant to manage fleets of aircraft) I saw a very neat form of testing. In this case the architect of the system wrote the major functionality in Python, based on the developed requirements. The development team implemented the same two core modules, which read the same inputs and generated the same outputs, in a C-based language to be served over the internet. The clever part was that the two core modules written by each of the players wrote out debug files that described every element they took as input and every element they generated as output. External comparator programs then automatically compared the two debug files for each of the two major modules and cataloged the exact differences between them. The number of elements compared for some of the elements was over 100,000. This testing could not prove that either system was correct per se, but if two developers could interpret the same set of requirements the same way, that could be a good indication that they were on the right track.
- I learned about Cucumber as I was qualifying for my CSD. That leverages specific statements in a list of business requirements that can be tested against.
- All of the control systems I wrote had to ensure that the furnace produced steel that would be rolled properly in the rolling mill. It also had to ensure that the temperatures predicted by the model and controlled to by the model had to match what could be physically measured. A system could theoretically calculate any number for steel temperature as long as control to that number resulted in steel that could be rolled properly. The number could be 37, 2140, or negative one million, but that would be very confusing. Therefore the system not only had to produce steel that could be rolled properly with a clean surface (that acceptance criteria was governed by a different part of the control system), the predicted surface temperature had to match the temperatures recorded by an infrared pyrometer as each piece of steel was discharged. This was more correct from an operational point of view and gave the users a much greater sense of confidence.
- Simulations could be verified in a couple of different ways. One was to see if a set of inputs will reproduce a known set of outputs, which come in many forms. Once it is agreed that the system matches known outputs the system is tested to see if novel sets of inputs result in outputs that make logical sense.
- In some cases the veracity and applicability of a tested system’s outputs can only be evaluated by subject matter experts (SMEs). In those cases you get them to work with the system and its outputs and have them attest to their acceptability in writing.
- The training simulators I helped build were contractually obligated to match the real plant’s operating indicators within 1% at steady state and to within 10% in transients. Verification of this behavior could only be carried out by experienced plant personnel interacting with the simulator as it ran.
- I worked on a project that first had to duplicate the results of the existing system exactly, even though some of the existing outputs were found to be in error. I was able to use the new system’s reporting functionality to compare roughly a 100,000 values from each system, which indicated that we understood the original model perfectly. We were then free to correct the errors in the original model.
Technical, Performance, and Reliability Tests
These tests address the behavior of the system as it is installed and examine qualities like performance, load, and security.
- I was directed to install a system on a plant computer that also hosted a database server. My system threw an alarm whenever it was not able to run within a certain period of time, and the alarms started showing up for a few minutes at a time two or three times a day. My system’s event logs told me when the events happened, but couldn’t tell me why. I figured out that the Performance Monitor program in Windows can archive the performance of a wide range of system resources and after a day or so I was able to figure out that a particular function of the database’s operation consumed so much CPU and disk I/O that little else was able to run. I ended up installing my suite of programs on a different computer that wasn’t hosting any processes that consumed too many resources.
- The pulping systems I supported were contractually required to be in operation 95% of the time. I helped create a different system that was allowed a specified maximum amount of downtime.
- Other systems I installed were expected to run more or less forever, though it was a good idea to reboot them during down periods. The systems I wrote for the steel industry had limited hard drive space that was easy to fill up with historical archive files. My solution was to add a process which periodically erased any such files above a certain age. The plant personnel were in charge of saving the relevant data to a more permanent location before it was lost.
The bottom line is that systems have to meet a wide range of logical and usability requirements and a wide range of test procedures are needed to examine each. The more tools there are in the tester’s toolbox the more quickly, completely, and accurately they’re going to be able to ensure they’ve got it right.