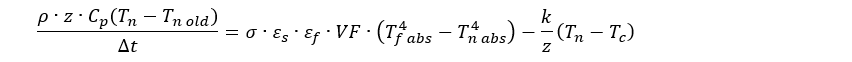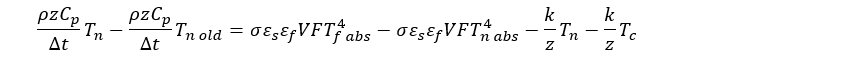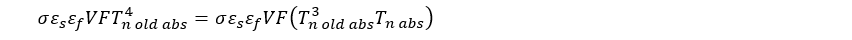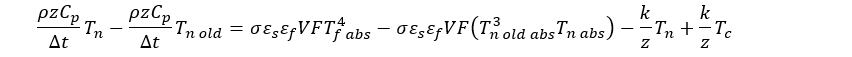I’ve been working on an introductory animation for my soon-to-be-released landing page (what, stumbling into a random WordPress post and a tiny resume link isn’t the pithiest possible introduction?), and I was looking around and playing with various ideas when I stumbled across this site and this video. This company makes what look to be a very impressive set of products with even more impressive licensing terms. However, since the point of this website, for now, is to help me learn new things when I’m not describing and recreating some of the work I’ve done from earlier in my career, I used the information presented as inspiration for creating my own basic animation framework.
The first thing I want to point out as I begin this week of related posts is that I haven’t looked at the company’s and product’s code at all. I’m just trying to recreate some basic functionality and use what I see as inspiration for my own explorations. The things I found helpful were the ideas embodied in the animation product. I would not assume that I’ve figured out exactly how they did what they did but I’ve definitely been able to recreate some of the same functionality in my own way. This is in keeping with my goal of ensuring that all the running code on this site is my own.
If you check out the linked video you see a tool that uses a very terse JavaScript syntax that produces very nice, very controllable effects. The key thing is that the animations produced run quickly and smoothly. I a) needed an animation and b) like to build tools so this was a natural thing to tackle.
I spent some of the past weekend building up a rather cumbersome first attempt at an animation framework. It was big and it was kludgy and it was slow and it sometimes hiccuped. I recognized that I needed a system that carried out the following steps:
- specify element
- specify initial properties
- specify final properties
- specify duration
- specify start time
- build list of commands that run for every animation call
What I originally came up with was a way to create an array with links bunch of elements, create arrays with transformation objects that describe what to do with each element, and a way to cycle through the lists of elements and transformations to see what needs to be done… during every animation step. Since the animation steps might be happening every 60th of a second on a modern device (possibly less often on an older machine… like a Palm Pre like maybe), you can imagine there’s quite a bit of overhead. I also made the original animation space rather large which involved long traversals that took up a decent amount of time. The original animations worked but they took a lot of code to express and like I said, they weren’t always very smooth. Then I noticed a couple of things that helped.
One was that the example animation shown in the linked video was comparatively small, and the transitions all happened rather quickly. I therefore resolved to make my intro animation much smaller. I chose a 400-by-400 pixel space for the animation, which fits my page and should look respectable on any modern device. I don’t promise that any example I develop during these experiments will run well (or even at all) on every device, in every browser, and on every OS, but it should work and look reasonable on anything current. I’m also assuming a 60 frames-per-second refresh rate. I’ll explain why tomorrow.
The other thing I noticed is that the verbiage on the company’s site spoke of creating tweens for each animation step. This suggested that the product wasn’t figuring out what to do during every animation step, but was probably pre-calculating the actions up front. I ended up rewriting something that was much, much more succinct in terms of code and ran a heck of a lot more smoothly.
It takes a certain amount of information to describe the actions to be taken, and the incredibly terse JavaScript that does so in the linked video seems to leave some of it out. Or, rather, it makes certain assumptions about where things begin and end. I created a function that linked to elements in the animation div (I made them all divs themselves but they could be anything and it would probably be more efficient if most of them weren’t divs) and another set of functions that calculate tweens and load them into a list of commands to be executed as the animation proceeds. It occurred to me that the JavaScript files written by the company probably do something similar, and the impossibly pithy code the users write is actually something that gets peeled apart, interpreted, and fed to a series of functions similar to what I wrote. I don’t know that to be true, I just feel like it might be.
The thing that ultimately makes the thing go, and go smoothly, is the list of commands to be processed during each animation step. Remember from a recent post that the basic animation loop works something like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
var maxAnimationSteps = ...; function doSomeStuff(step) {...} var animationStep = 0; var requestId; function animateSomeStuff() { doSomeStuff(animationStep); if (animationStep >= maxAnimationSteps { cancelAnimationFrame(requestId); } else { animationStep++; } requestId = window.requestAnimationFrame(animateSomeStuff); } animateSomeStuff(); |
What you want, therefore, is the pithiest possible set of commands to run in the doSomeStuff call. I use the animationStep variable as an index into the array of animation commands I set up prior to kicking off the animation loop. The array of animation commands has two dimensions, one for each animation step, and one for each command issued during that step. (I happened to reserve element zero in each secondary array for holding the number of commands to be issued but that isn’t strictly necessary.) When the animation runs for each time step all it has to do is cycle through the list of activities that has to be performed during that animation step.
So, how do you–pithily–tell the program how to manipulate some aspect of an HTML element? Wouldn’t it be nice if we had access to something simple like:
|
1 |
document.getElementById("nameOfItem").style.cssProperty = value; |
…where we could refer to a known JavaScript handle, a specific property, and a specific value? Well, using the concept of automatic code generation it’s a simple matter to generate a bit of text like the following, which represents a valid line of JavaScript code that can be stored in the second dimension of the array of animation commands.
“handle001.style.left = ‘117px’;”
I also happened to be reading through some advice on JavaScript programming, which says to NOT use the eval() command, but this seemed almost too good to be true. If we feed the generated string to the eval command we can do just about anything. There may be some overhead from using this method, but it certainly gets the job done.
It is entirely possible that the good people at Greensock came up with a better way to do this, and I’m sure that there are, in fact, many ways to accomplish this sort of thing. This method does have the virtue of being compact and straightforward, and, most importantly, it more or less works.
I’ll go into more detail in subsequent posts but here is a very simple example of the process in action.
The red line slides in from the left over one second starting from time zero. The blue line drops down from the bottom over two seconds starting from the 0.5-second mark. All parameters are settable.
As I look at this I see that the process keeps hitching and hiccuping, so it’s very likely that I’m missing something. It’s possible that the eval() function is not the best way to do things, and it’s also possible that the problem lies elsewhere. The elements I’m moving are divs, which require more overhead to move than just raw HTML elements, and I’m also updating every element during every animation step (60 fps on modern devices). It’s possible that I can skip animation steps and still get decent effects.