
How Different Management Styles Work
Solutions, and let’s face it, those quite often involve the development and modification of software these days, can be realized in the context of many different types of organization. A lot of bandwidth is expended insisting that everything be done in a specific Agile or Scrum context, and people can get fairly militant about how Scrum processes should be run. I tend to be a little more relaxed about all that, figuring that correctly understanding a problem and designing an excellent solution is more important than the details of any management technique, and here’s why.
Beginning at the beginning, my framework lists a group of major steps to take: intended use, conceptual model, requirements, design, implementation, and testing. (I discuss the framework here, among other places.) While there are a few ancillary steps involving planning, data, and acceptance, these are the major things that have to get done. The figure below shows that each step should be pursued iteratively until all stakeholders agree that everything is understood and complete before moving on. Moreover, the team can always return to an earlier step or phase to modify anything that might have been missed in an earlier phase. This understanding should be maintained even as we discuss different configurations of phases going forward.

The most basic way to develop software, in theory, is through a Waterfall process. In this style of development you march through each phase in order, one after another, and everyone goes home happy, right?
Riiiiiight…
No one ever really developed software that way. Or, more to the point, no one did so with much success on any but the most trivial projects. There was always feedback, learning, adjustment, recycling, and figuring stuff out as you go. The key is that people should always be working together and talking to each other as the work progresses, so all parties stay in sync and loose ends get tied up on the fly. There are a lot of ways for this process to fail, and most of them involve people not talking to each other.
A significant proportion of software projects fail. A significant proportion of software projects have always failed. And a significant proportion of software projects are going to go right on failing — and mostly for the same reason. People don’t communicate.
Running Scrum or Agile or Kanban or Scrumban or WaterScrum or anything else with a formal definition isn’t a magic bullet by itself. I’ve seen huge, complicated Scrum processes in use in situations where stuff wasn’t getting done very efficiently.
So let’s look at some basic organization types, which I diagram below, using the basic six phases I list above.

Waterfall is the traditional form of project organization, but as a practical matter nobody ever did it this way — if they wanted their effort to be successful. First of all, any developer will perform an edit-compile-test cycle on his or her local machine if at all possible. Next, individuals and teams will work in a kind of continuous integration and test process, building up from a minimum core of running code and slowly expanding until the entire deliverable is complete.
So what defines a waterfall process? Is it defined by when part of all of the new code runs or when new code is delivered? Developing full-scope nuclear power plant training simulators at Westinghouse was a long-term effort. Some code was developed and run almost from the beginning and code was integrated into the system through the whole process but the end result wasn’t delivered until the work was essentially complete, shipped to the site, and installed about three years later. The model-predictive control systems I wrote and commissioned were developed and deployed piecemeal, often largely on-site.
My point isn’t to argue about details, it’s to show there’s a continuum of techniques. Pure methodologies are rarely used.
The main point of Agile is to get people talking and get working code together sooner rather than later, so you aren’t just writing a whole bunch of stuff and trying to stick it together at the very end. The Agile Manifesto was a loose confederation of ideas by seventeen practitioners in 2001 who couldn’t agree on much else. The four major statements are preferences — not absolute commandments.

People get even more wound up in the practice of Scrum. It seems to me that people who’ve only been in one or two organizations think that what they’ve seen is the only way to do things. They tend to think that asking a few trivia questions is a meaningful way to gauge someone else’s understanding. Well, I’ve seen the variety of different ways organizations do things and I know that everything written in the Scrum manuals (the training manuals I got during my certification classes are shown above and all can be reviewed in 10-15 minutes for details once you know the material) should be treated more as a guideline or a rule of thumb rather than an unbreakable commandment. In fact, I will state that if you’re treating any part of the Scrum oeuvre as an unbreakable commandment you’re doing it wrong. There are always exceptions and contexts and you’d know that if you’ve seen enough.
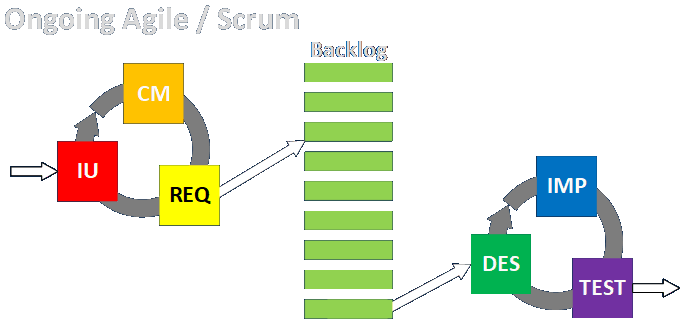
I showed the Scrum process, in terms of my six major engagement phases, as a stacked and offset series of Waterfall-like efforts. This is to show that a) every work item needs to proceed through all phases, and more or less in order, b) that not all the work proceeds in order within a given sprint; items are pulled from a backlog of items generated during intended use, conceptual model, and requirements phases which are conducted separately (and which could be illustrated as a separate loop of ongoing activities), and c) and that work tends to overflow from sprint to sprint depending on how the specific organization and deployment pipeline is set up. A small team working on a desktop app might proceed through coding, testing, and deployment of all items in a single sprint. A larger or more distributed team, especially where coders create work items that are submitted to dedicated testers, might complete coding and local testing in one sprint, while the testers will approve and deploy those items in the next. If there is a long, multi-stage development and deployment process, supporting multiple teams working in parallel and serially, like you’d find in a DevOps environment supporting a large-scale web-based operation, then who knows how long it will take to get significant items though the entire pipeline? And how does that change if significant rework or clarification is needed?
A lot of people also seem to think their environment or their industry is uniquely complex, and that other types of experience aren’t really translatable. They don’t necessarily know about the complexities other people have to deal with. I’ve written desktop suites of applications that require every bit as much input, care, planning, real-time awareness, internal and external integration, mathematical and subject matter acumen, cyclic review, and computer science knowledge as the largest organizational DevOps processes out there. What you’re doing ain’t necessarily that special.
All projects, even in software development, are not one-size-fits all. As I stress in the talks I give about my business analysis framework, the BABOK is written in a diffuse way precisely because the work comes in so many different forms. There is no cookie cutter formula to follow. Even my own work is just restating the material in a different context. Maybe the people I’ve been interacting with know that, but whatever they think I’m not communicating to them, there’s surely been a lot they haven’t communicated to me. Maybe that’s just because communication about complex subjects is always difficult (and even simple things, all too often), or maybe a lot of people are just thinking inside their own boxes.
This figure above can also be used to represent an ongoing development or support process as it’s applied to an already working system. This can take the form of Scrum, Kanban, Scrum-Ban, or any other permutation of these ideas. Someone recently asked me what I thought the difference between Scrum and Kanban was, and I replied that I didn’t think it was particularly clear cut. I’ve seen a lot of descriptions (including talks at IIBA Meetups) about how each methodology can be used for native development and for ongoing support. The biggest difference I’d gathered was that Kanban was more about work-metering, or managing in the context of being able to do a relatively fixed amount of work in a given time with a relatively fixed number of resources, while Scrum was more flexible and scalable depending on the situation. A search of the differences between Scrum and Kanban turns up a fairly consistent list of differences — none of which I care about very much. Is there anything in any of those descriptions which experienced practitioners couldn’t discuss and work out in a relatively short conversation? Moreover, is that material anywhere near as important as being able to understand customers’ problems and developing phenomenal solutions to them in an organized, thorough, and even stylish way, which is the actual point of what I’ve been doing for the last 30-plus years, in a variety of different environments? Moreover, referring to my comment above that if you’re doing things strictly by the book you’re probably doing it wrong, I have to ask whether things don’t always end up as a hybrid anyway, or that you don’t adapt as needed? I’ve commented previously that the details of specific kinds of Agile organizations are about one percent of doing the actual analysis and solutioning that provides value. That’s not likely to make a lot of people happy, least of all the screeners who congratulate themselves for supposedly being able to spot fraudulent Scrum practitioners, but that’s where I come down on it. While those folks are asking about things that don’t matter much, they’re failing to understand things that do.
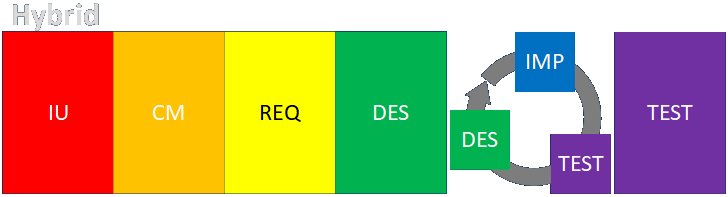
Another problem with the Agile and Scrum ways of thinking is that some people might think that you might need to do some initial planning in a Sprint Zero but then you can be off and running and making meaningful deliveries shortly thereafter. I hope people don’t think that, but I wanted to show a hybrid Waterfall-Scrum-like process to illustrate how Scrum techniques can be used in a larger context where an overall framework is definitely needed. In such a scenario, a significant amount of intended use, conceptual modeling, requirements, and design work has to be done before any implementation can begin, and there will need to be significant integration and final acceptance testing at the end, some of which may not be able to be conducted until all features are implemented. In the middle of that, however, a Scrum-like process can be used to strategically order work items for incremental development, with some time allowed for low-level, local design and unit and integration testing. The point is never to follow a prescription from someone’s book, but to do what makes sense based on what you actually need.
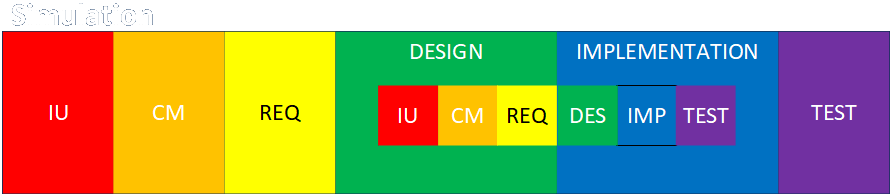
If you’re doing simulation, either as the end goal of an engagement or as a supporting part of an engagement, the construction of a simulation is a separate project on its own, and that separate project requires a full progression through all the standard phases. I don’t show a specific phase where the simulation is used, that’s implied by the phase or phases in which the construction of the simulation is embedded. If the individual simulations used in each analysis have to be built or modified by a tool that builds simulations, then the building (and maintenance) of the tool is yet another level of embedding. Tools to create simulations can be used for one-offs by individual customers, but they are often maintained and modified over long periods of time to support an ongoing series of analyses of existing processes or projects.
In the diagram I show the construction of the simulation as being embedded in the design and implementation phases of a larger project, but that’s just a starting point. Let’s look at some specific uses of simulation (and I’ve done all of these but the last two, almost always with custom simulations stick-built in various high-level languages, and often that I’ve written personally in whole or in part), and see how the details work out. I describe the following applications of simulation in detail here, and I can tell ahead of time that there’s going to be some repetition, but let’s work through the exercise to be thorough.
-
Design and Sizing: In this case the construction and use of the simulation in all within the design phase of the larger project. I used an off-the-shelf package called GEMS to simulate prospective designs for pulping lines at my first engineering job. It was the only off-the-shelf package I ever used. Everything else was custom.
-
Operations Research: This usually, but not always, involved modelling a system to see how it would behave in response to changes in various characteristics. Here are a few of the efforts we applied it to at two of my recent stops.
-
We used a suite of model-building tools called BorderWizard, CanSim, and SimFronteras to build models of almost a hundred land border ports of entry on both sides of both U.S. borders — and one crossing on Mexico’s southern border with Guatemala. The original tool was created and improved over time and used to create baseline models of all the ports in question. That way, when an analysis needed to be done for a port, the existing baseline model could be modified and run and the output data analyzed.
The creation, maintenance, and update of the tools was a kind of standalone effort. The creation of the individual baselines all sprang from a common intended use phase but proceeded through all the other phases separately. The building of each crossing’s baseline is embedded as a separate project in the analysis project’s conceptual model phase.
The individual analyses are what is represented in the header diagram for this section. Each standalone analysis project proceeded through its own intended use, conceptual model, and requirements phases. Updating the configuration of the model based on the needs of the particular analysis was embedded in the design phase of the analysis project. Using the results of the model runs to guide the modifications to the actual port and its operations was embedded in the implementation phase of the analysis project. The test phase of the analysis or port improvement project involved seeing whether the changes made met the intended use.
I participated in a design project to determine the requirements for and test the performance of proposed designs for the the facilities on the U.S. side of an entirely new crossing on the border between Maine and Canada. This work differed from our typical projects only in that we didn’t have a baseline model to work from.
-
The work we did on aircraft maintenance and logistics using (what we called) the Aircraft Maintenance Model (AMM) proceeded in largely the same way, except that we didn’t have a baseline model to work from. Instead, the input data to the one modeling engine that was used for all analyses were constructed in modular form, and the different modules could be mixed and matched and modified to serve the analysis at hand. We did have a few baseline input data components, but most of the input components had to be created from scratch from historical data and prevailing policy for each model run.
-
I had a PC version of the simulation I used to install on DEC machines at plants requesting that hardware. I’d develop it on the PC first to get all the parameters right, and then I’d re-code that design for the new hardware, in whatever language the customer wanted (the PC code was in Pascal, the customers wanted FORTRAN, C, or C++ at that time). One of our customers, in a plant in Monterrey, Mexico, which I visited numerous times over the course of two installations (my mother died while I was in the computer room there), saw the PC version and wondered if it could be used to do some light operations research, since it included all the movement and control mechanisms along with the heating mechanisms, and it had a terrific graphic display. We ended up selling them a version of the desktop software as an add-on, and they apparently got a lot of use out of it.
My creation of the PC version of the software for design and experimentation was embedded in the conceptual model, requirements, and design phases of larger control system projects. Adapting it so it could be used by the customer was a standalone project in theory, though it didn’t take much effort.
-
We built simulations we used to analyze operations at airports and to determine staffing needs in response to daily flight schedule information we accessed (the latter could be thought of as a form or real-time control in a way). That simulation was embedded in a larger effort, probably across the requirements, design, and implementation phases.
-
-
Real-Time Control: Simulations are used in real-time control in a lot of different contexts. I’ve written systems that contained elements that ran anywhere from four times a second to once per day. If decisions are made and actions taken based on the result of a time-bound simulation, then it can be considered a form of real-time control.
The work I did in the metals industry involved model-predictive simulation. The simulation was necessary because the control variable couldn’t be measured and thus had to be modeled. In this case the simulation wasn’t really separate from or embedded within another project, it was, from the point of view of a vendor providing a capability to a customer, the point of the deliverable. The major validation step of the process, carried out in the test phase of my framework, is ensuring that the surface temperatures of the discharged workpiece match what the control system supposedly calculated and controlled to. The parameters I was given and the methods I employed were always accurate, and the calculated values always matched the values read by the pyrometer. The pyrometer readings could only capture the surface temperature of the workpieces, so a second validation was whether the workpieces could be properly rolled so the final products had the desired properties and the workpieces didn’t break the mill stands.
-
Operator Training: Simulations built for operator training are usually best thought of as ends in themselves, and thus often should be thought of as standalone projects. However, the development and integration of simulations for this purpose can be complex and change and grow over extended periods of time, so there can be multiple levels of context.
-
The nuclear power plant simulators I helped build worked the same way as the control systems I wrote for the metals industry, except that they were more complicated, involved more people, and took longer to finish. The simulation was itself the output, along with the behavior of the control panels, thus building the simulations were part and parcel of the finished, standalone product. They weren’t something leveraged for a higher end. The same is true for flight simulators, military weapon simulators, and so on.
-
We made a plug-in for an interactive, multi-player training simulator used to examine various threat scenarios in different kinds of buildings and open spaces. The participants controlled characters in the simulated environment much like they would in a video game. Our plug-in autonomously guided the movements of large number of people as the evacuated the defined spaces according to defined behaviors. In terms of the our customer’s long-term development and utilization of the larger system our effort would be considered to be embedded in the design and implementation phases of an upgrade to their work. In terms of our developing the plug-in for our customer, it seemed like a standalone project.
-
-
Risk Analysis: Risk can be measured and analyzed in a lot of ways, but the most common I’ve encountered is in the context of Monte Carlo simulations, where results are expressed in terms of the percentage of times a certain systemic performance standard was achieved, and in operator training, where the consequences of making mistakes can be seen and trainees can learn the importance of preventing adverse scenarios from happening.
-
Economic Analysis: Costs and benefits can be assigned to every element and activity in a simulation, so any of the contexts described here can be leveraged to support economic calculations. Usually these are performed in terms of money, which is pretty straightforward (if you can get the data) but other calculations were performed as well. For example, we modified one of our BorderWizard models to total up the amount of time trucks sat at idle as they were waiting to be processed in the commercial section of a border crossing in Detroit, so an estimate could be made of the amount of pollution that was being emitted, and how much it might be reduced if the truck could be processed more quickly.
-
Impact Analysis: Assessing the change in behavior or outputs in response to changes in inputs is essentially gauging the impact of a proposed change. This applies to any of the contexts listed her.
-
Process Improvement: These are generally the same as operations research simulations. The whole point of ops research is process improvement and optimization, though it sometimes involves studies of feasibility and cost (to which end see economic analysis, above).
-
Entertainment: Simulations performed for entertainment can be thought of as being standalone projects if the end result is used directly, as in the case of a video game or a virtual reality environment. If the simulation is used to create visuals for a movie then it might be thought of as an embedded project during the implementation phase of the movie. If the simulation is used in support of something else that will be done for a movie, for example, the spectacular car-jump-with-a-barrel-roll stunt the the James Bond movie “The Man With the Golden Gun,” then it might be thought of as being embedded in the larger movie’s design phase. The details of what phase things are in aren’t all that important, as the context is intuitively obvious when you think about it. We’re just going through the examples as something of a thought experiment.
-
Sales: Simulations are often used to support sales presentations, and as such might have to look a little spiffier than the simulations working analysts (who understand the material and are more interested in the information generated than they are in the visual pizazz) tend to work with. If an existing simulation can’t be used, then the process of creating a new version to meet the new requirement may be thought of as a standalone project.
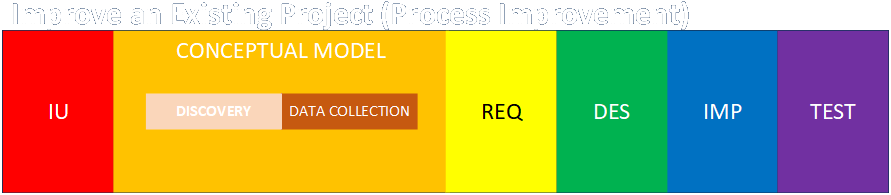
If a project involves improving an existing process, then the work of the analyst has to begin with understanding what’s already there. This involves performing process discovery, process mapping, and data collection in order to build a conceptual model of the existing system. Work can then proceed to assess the methods of improvements and their possible impacts.
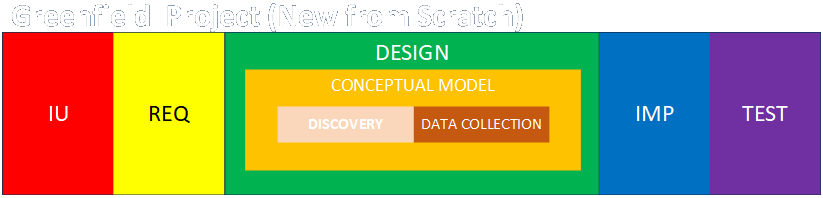
If a project involves creating a new operation from the ground up, then the conceptual modeling phase is itself kind of embedded in the requirements and design phases of the new project. The discovery, mapping, and data collection phases will be done during requirements and design. That said, if some raw material can be gleaned from existing, analogous or competitive projects elsewhere, then this initial background research could be thought of as the conceptual modeling phase.
Conclusion
This exercise might have been a bit involved, but I think it’s important to be able to draw these distinctions so you have a better feel for what you’re doing and when and why. I slowly learned about all these concept for years as I was doing them, but I didn’t have a clear understanding of what I was doing or what my organization was doing. That said, getting my CBAP certification was almost mindlessly easy because I’d seen everything before and I had ready references and examples for every concept the practice of business analysis supposedly involves. The work I’ve done since then, here in these blog posts and in the presentations I’ve given, and all I’ve learned from attending dozens of talks by other BAs, Project Managers, and other practitioners, has continued to refine my understanding of these ideas.
Looking back based on what I know now, I see where things could have been done better. It might be a bit megalomaniacal to describe these findings as a “Unified Theory of Business Analysis,” but the more this body of knowledge can be arranged and contextualized so it can be understood and used more easily and effectively, then I think it’s useful.
If you think this material is great, tell everyone you know. If you think it sucks, tell me!