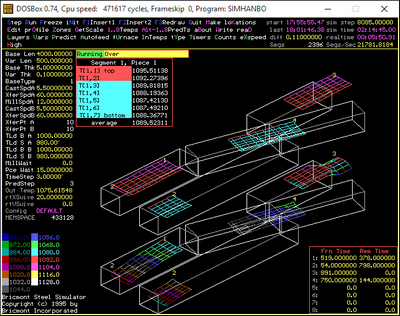
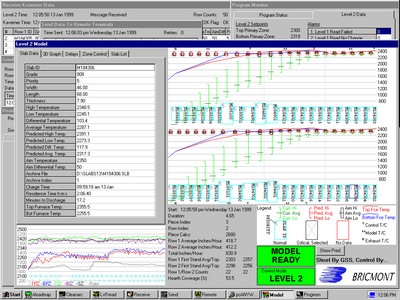
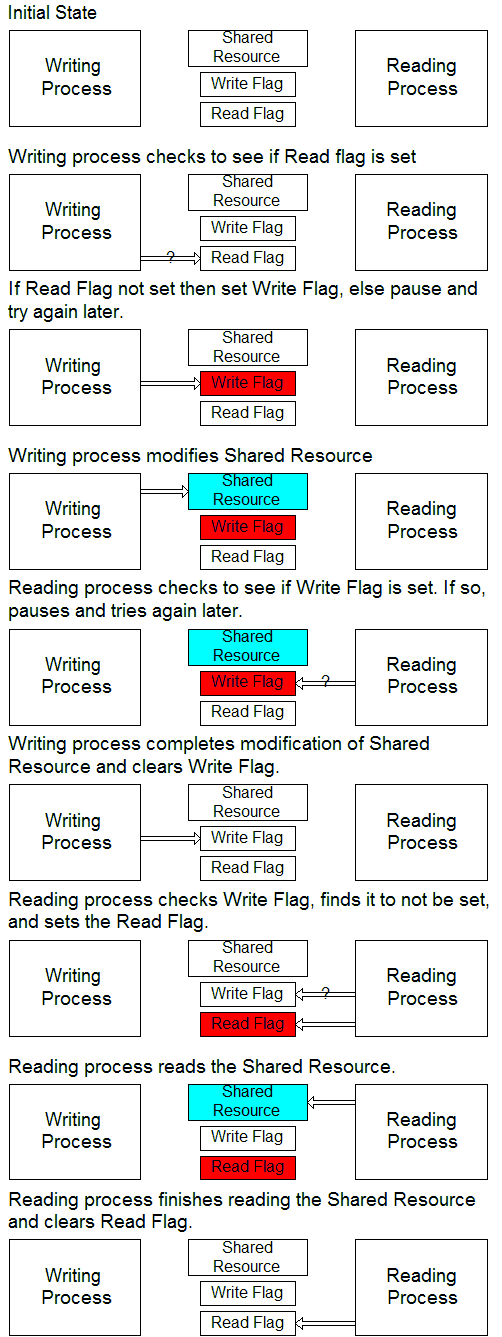
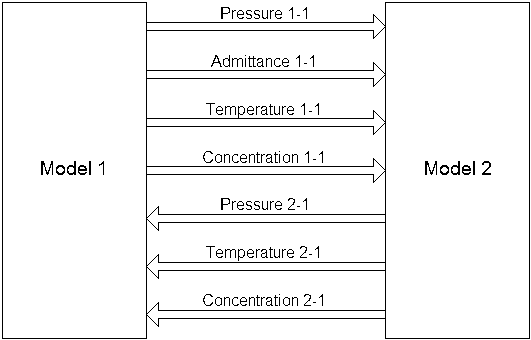
//entity item passive
//stores minimal state information, does nothing on its won
function EntityPassive(entityType,parentEntity) {
if (typeof parentEntity === "undefined") {parentEntity = null}
this.entityID = getNewEntityID();
this.entryTime = globalSimClock;
this.entityType = entityType;
var p = [];
for (var i=0; i<numEntityProperties; i++) {
p[i] = 0;
}
this.propertyList = p;
this.entityColor = "#FFFFFF"; //default color, should set this based on its properties
this.localEntryTime = 0.0;
this.localIndex = -1;
this.componentGroup = "";
this.componentGroupEntryTime = 0.0;
this.xLocation = 0.0;
this.yLocation = 0.0;
this.permissionToMove = false;
this.forwardAttemptTime = Infinity;
this.parentEntity = parentEntity;
/* this.getEntityID = function() {
return this.entityID;
};
this.getEntryTime = function() {
return this.entryTime;
};
this.setLocalEntryTime = function() {
this.localEntryTime = globalSimClock;
};
this.getLocalEntryTime = function() {
return this.localEntryTime;
};
this.setLocalIndex = function(index) {
this.localIndex = index;
}
this.getLocalIndex = function() {
return this.localIndex;
}
this.setComponentGroup = function(componentGroup) {
this.componentGroup = componentGroup;
};
this.getComponentGroup = function() {
return this.componentGroup;
};
this.setComponentGroupEntryTime = function(componentGroupEntryTime) {
this.componentGroupEntryTime = componentGroupEntryTime;
};
this.getComponentGroupEntryTime = function() {
return this.componentGroupEntryTime;
};
this.getEntityType = function() {
return this.entityType;
};
this.setPropertyValue = function(propertyName,propertyValue) {
var i = 0;
while ((i < numEntityProperties) && (propertyName != entityProperties[i][0])) {
i++;
}
if (i < numEntityProperties) {
this.propertyList[i] = propertyValue;
} else {
alert("Trying to set out of range entity property");
}
};
this.getPropertyValue = function(propertyName) {
var i = 0;
while ((i < numEntityProperties) && (propertyName != entityProperties[i][0])) {
i++;
}
if (i < numEntityProperties) {
return this.propertyList[i];
} else {
alert("Trying to get out of range entity property");
}
};
this.setLocation = function(xloc, yloc) {
this.xLocation = xloc;
this.yLocation = yloc;
};
this.getLocation = function() {
return {x: this.xLocation, y: this.yLocation};
};
this.setPermission = function(permission) {
this.permissionToMove = permission;
};
this.getPermission = function() {
return this.permissionToMove;
};
this.getForwardAttemptTime = function() {
return this.forwardAttemptTime;
};
this.setForwardAttemptTime = function(forwardAttemptTime) {
this.forwardAttemptTime = forwardAttemptTime;
};
this.setEntityColor = function(color) {
this.entityColor = color;
};
this.getEntityColor = function() {
return this.entityColor;
};
this.drawEntity = function() { //(entityColor) {
//in this case x and y are absolute screen coords
drawNode(this.xLocation, this.yLocation, 5, this.entityColor);
}; */
} //EntityPassive
EntityPassive.prototype.getEntityID = function() {
return this.entityID;
};
EntityPassive.prototype.getEntryTime = function() {
return this.entryTime;
};
EntityPassive.prototype.setLocalEntryTime = function() {
this.localEntryTime = globalSimClock;
};
EntityPassive.prototype.getLocalEntryTime = function() {
return this.localEntryTime;
};
EntityPassive.prototype.setLocalIndex = function(index) {
this.localIndex = index;
};
EntityPassive.prototype.getLocalIndex = function() {
return this.localIndex;
};
EntityPassive.prototype.setComponentGroup = function(componentGroup) {
this.componentGroup = componentGroup;
};
EntityPassive.prototype.getComponentGroup = function() {
return this.componentGroup;
};
EntityPassive.prototype.setComponentGroupEntryTime = function(componentGroupEntryTime) {
this.componentGroupEntryTime = componentGroupEntryTime;
};
EntityPassive.prototype.getComponentGroupEntryTime = function() {
return this.componentGroupEntryTime;
};
EntityPassive.prototype.getEntityType = function() {
return this.entityType;
};
EntityPassive.prototype.setPropertyValue = function(propertyName,propertyValue) {
var i = 0;
while ((i < numEntityProperties) && (propertyName != entityProperties[i][0])) {
i++;
}
if (i < numEntityProperties) {
this.propertyList[i] = propertyValue;
} else {
alert("Trying to set out of range entity property");
}
};
EntityPassive.prototype.getPropertyValue = function(propertyName) {
var i = 0;
while ((i < numEntityProperties) && (propertyName != entityProperties[i][0])) {
i++;
}
if (i < numEntityProperties) {
return this.propertyList[i];
} else {
alert("Trying to get out of range entity property");
}
};
EntityPassive.prototype.setLocation = function(xloc, yloc) {
this.xLocation = xloc;
this.yLocation = yloc;
};
EntityPassive.prototype.getLocation = function() {
return {x: this.xLocation, y: this.yLocation};
};
EntityPassive.prototype.setPermission = function(permission) {
this.permissionToMove = permission;
};
EntityPassive.prototype.getPermission = function() {
return this.permissionToMove;
};
EntityPassive.prototype.getForwardAttemptTime = function() {
return this.forwardAttemptTime;
};
EntityPassive.prototype.setForwardAttemptTime = function(forwardAttemptTime) {
this.forwardAttemptTime = forwardAttemptTime;
};
EntityPassive.prototype.setEntityColor = function(color) {
this.entityColor = color;
};
EntityPassive.prototype.getEntityColor = function() {
return this.entityColor;
};
EntityPassive.prototype.drawEntity = function() { //(entityColor) {
//in this case x and y are absolute screen coords
drawNode(this.xLocation, this.yLocation, 5, this.entityColor);
};