
This was the first question I was asked in an interview sometime around 2006. I didn’t know the answer, which is exceptionally annoying because I’d been using them for years without knowing what they were called. This is a danger of not having read enough of the right materials or of being trained as a mechanical engineer and then as a programmer rather than a pure computer scientist from the get-go. Take your pick.
Mutex is a portmanteau of the words “mutual exclusion.” What this describes in practice is a mechanism for ensuring that multiple processes cannot inappropriately interact with a common resource. This usually means that multiple processes cannot change a common resource at the same time, since doing so may break things in a big way (see the example from the Wikipedia link describing what can happen when two processes are trying to remove adjacent elements from a linked list). Another way this comes up is when a writing process needs to update multiple common elements that describe a consistent state and needs to prevent one or more reading processes from reading the data while the write process is underway. Under some circumstances it’s just fine to allow multiple reading processes to access a shared resource, but the state has to remain consistent.
Let’s visualize how this works. We’ll do this in a general way and then describe some specific variations in how this concept can be implemented.
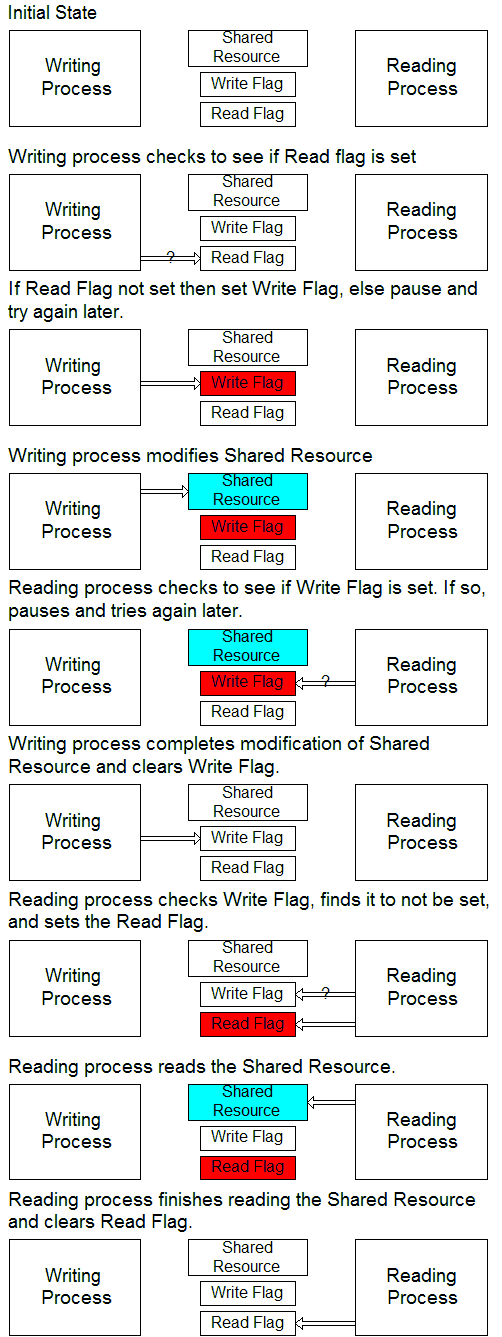
The details of this process can very widely:
- The “Writing” and “Reading” processes can, in fact, be performing any kind of operation, though this should only be an issue if at least one of the processes is writing (this means modifying the shared resource). What’s really important is that both processes should not be accessing the shared resource at the same time.
- The flags can be separate items or a single item made to take on different values to reflect its state.
- The flags can be variables stored in a specified location in memory, files on a local or remote disk, entries in a database table, or any other mechanism. I have used all of these.
- The different processes that modify and read the data can be threads in the same program, programs on the same machine, programs or threads running on different CPU cores, or processes running on different machines (which would have to be connected by some sort of communication link).
It’s good practice to observe a few rules:
- A process should access the shared resource for the minimum possible time. Don’t lock the resource, read an item from it or write an item to it, do some stuff, read or write another item, do some more stuff, and so on: write or read and store local copies of everything at once and release the resource.
- You should be aware of how long processes are supposed to take and implement means of resetting flags left set when things go wrong.
One of my first jobs was writing thermo-hydraulic models for nuclear power plant simulators (oh yeah, I knew there was a reason I was a mechanical engineer first and a software engineer second…) that were implemented on systems that had four CPU cores and a memory space shared by all, so I got an early education in real-time computing. The modelers and utility engineers had to define interfaces that would allow models to exchange information. A simplified version of a model interface is shown below.
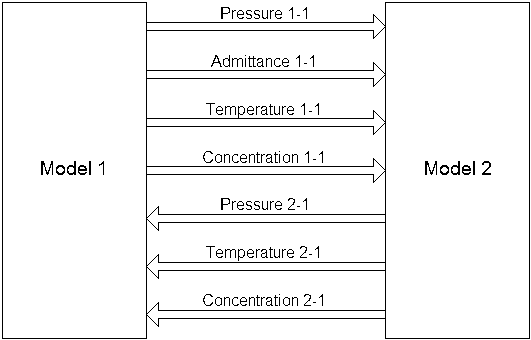
These bits of information might be used to model a single fluid flow between two plant systems. Fluid flow is a function of the square root of the pressure difference between two points (that is, if you want twice the flow you have to push four times as hard). The modelers know that the flow will always and only be subcooled liquid water so specifying the temperature also allows each model to calculate the thermal energy moving between systems. The concentration is a normalized number that described the fraction of the mass flow that is something other than water (in a nuclear power plant this might be Boron, a basic kind of radiation, a trace noncondensable gas, or something else). Both models must supply a pressure value to describe what’s happening at their end of the connecting pipe. Both models must supply values for temperature and concentration because the flow might go in either direction, based on which pressure is higher. Finally, only one model provides a value for the admittance, which considers the geometry of the pipe, the position of valves, the viscosity of the water, and the square root function, because that provides a more stable and consistent value.
So why do we care about details like this? Well, models take a finite amount of time to run, and they do things in a certain order. For example, a fluid model will read in the interface values from a number of other models in the simulator. Then it will calculate the flows in every link within its boundaries using a pressure-admittance calculation. Then it will use the flow information to calculate how much energy is carried to each region within the model so new temperatures can be calculated. Then a similar procedure will be used to update the values for concentrations in each internal region. Once that’s all done the model would copy all values that need to be read by other models into dedicated variables used for just that purpose.
Compressing the reading and writing of interface variables into the smallest possible time windows makes it far less likely that model 2 will be trying to read while model 1 is writing the updated values. This would be much more likely if model 1 weren’t copying all of its interface values to a special area of memory in a narrow slice of time rather than simply updating those values after each described series of calculations. If model 2 copied model 1’s interface variables over time then some of the variables (maybe the pressure and admittance) would represent a state from the current time step, while other variables (the temperature and concentration in this example) would reflect the state left over from the previous time step. This would be bad practice because the simulation would be likely to lose its ability to conserve mass and energy across all its models, and would generate increasingly large errors over time.
The systems we worked on at Westinghouse didn’t actually use mutexes, I didn’t use them formally until I started writing model-predictive control systems for steel reheat furnaces a couple of years later. The Westinghouse models usually had to rely on being made to run at different times to maintain protection from state corruption. The diagram below describes a simplified version of what was going on. Some utility routines (we called them “handlers”), like the ones used to sense actions by operators pushing buttons, would run as often as sixteen times a second to make sure no physical operator interactions could be missed. Most models of the plant’s electrical and fluid systems ran two or four times per second, while a handful of low-priority models ran only once per second.
Let’s suppose model 1 (shown in red) is set to run in CPU 1 at the rate of twice per second. The diagram shows one second of execution for each CPU. Where should we set up model 2 (possible positions of which are shown in light blue) to run so we know it won’t try to read or write interface variables at the same time as model 1? The diagram shows that models running in the same CPU will never run at the same time (they are all run naively straight through). It also shows that we should try to change the order (and frequency) of executions within each CPU to minimize conflicts.
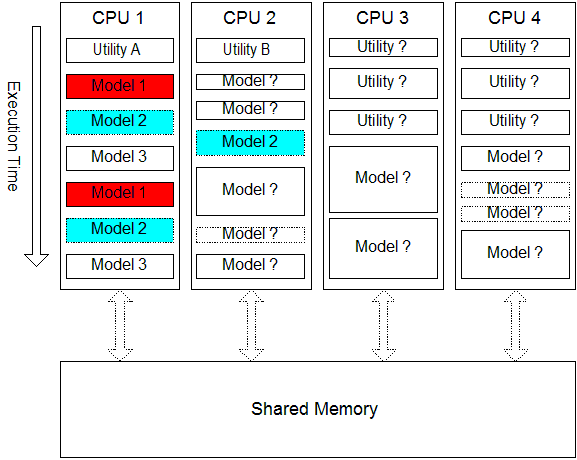
Given that such simulators modeled up to fifty fluid systems, a dozen-ish electrical systems, and hundreds of I/O points, pumps, valves, bistables, relays, and other components it’s easy to see that there’s only so much that can be done to hand-order the execution of different model codes. The problem is made even more difficult by the fact that the execution time of any model can vary from execution to execution depending on which branches are taken. Therefore, compressing the window of time during which any model or process needs to access its interface variables the more the state integrity of the system will be protected. You can picture that on the diagram above by imagining the reading and writing of interface variables to take up just a small sliver of time at the top and bottom (beginning and end) of each model iteration. The narrower the slivers the less likely there is to be unwanted overlap.
The consequences of losing this integrity might not be that meaningful in the context of a training simulator, but if things get out of sync in an industrial control system, particularly one that controls heavy objects, operates at extreme temperatures, or involves hazardous materials the consequences can be severe. You don’t want that to happen.
The beginning of this article discussed explicit mutexes, access locks that use an explicit change of state to ensure the state integrity of shared resources. The latter part of the article discusses implicit mutexes, which may not even be “a thing” discussed in the formal literature but of which the system engineer must be aware. Some of the considerations described apply to both types.