Many business processes require decisions to be made. Decision modeling is about the making and automating of repeatable decisions. Some decisions require unique human judgment. They may arise from unusual or entrepreneurial situations and involve factors, needs, and emotions that cannot reasonably be quantified. Other decisions should be made the same way every time, according to definable rules and processes.
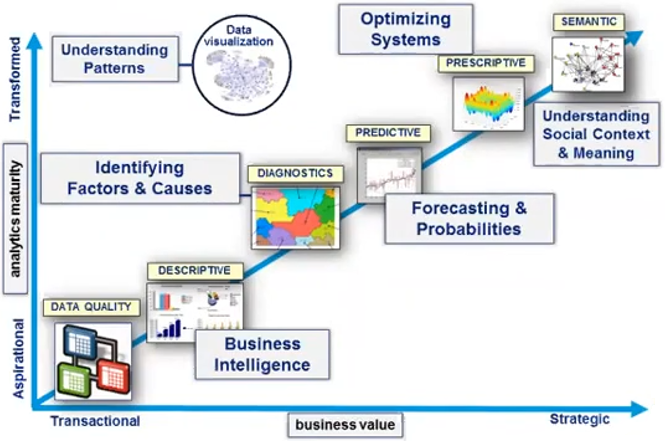
Decisions are made using methods of widely varying complexity. Many of the simulation tools I created and used were directed to decision support. The most deterministic and automatable decisions tend to use the techniques toward the lower left end of the trend toward complexity and abstraction for data analysis techniques shown above, although the ability to automate decisions is slowly creeping up and to the right. I discussed some aspects of this in a recent write-up on data mining.
Decision processes embody three elements. Knowledge is the procedures, comparisons, and industry context of the decision. Information is the raw material and comparative parameters against which a decision is made. The decision itself is the result of correctly combining the first two. Business rules can involve methods, parameters, or both.
Let’s see how some of these methods may work in practice.
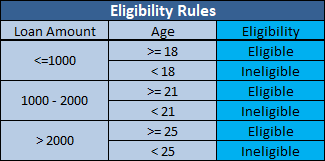
Decision trees, an example of which is shown above, list the relevant rules in terms of operations and parameters. The rules shown above involve simple comparisons, but more complex definitional and behavioral rules can apply. The optimization routines Amazon uses to determine how to deliver multiple items ordered at the same time in one or many shipments on one or many days and from one or more fulfillment centers involved up to 60,000 variables in the late-90s and are likely to be even larger now. A definitional rule may describe the way a calculation should be performed, while a behavioral rule might require a payment address to match a shipping address. The procedures and comparisons can be as complex as the situation demands.
The same set of rules can be drawn in the form of a decision tree as shown below.
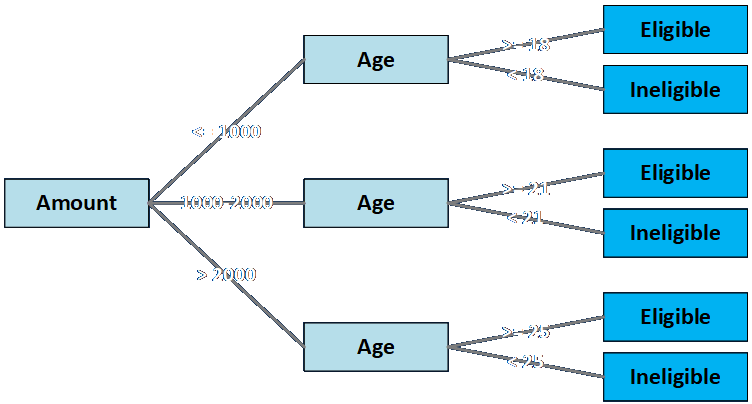
These rules can be described during the discovery and data collection activities of the conceptual model phase, and also during the requirements and design phases. It is fascinating how many different ways such rules can be brought to life in the implementation phase.
The most direct and brute force way is shown below, in the C language.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
bool IsEligibleForLoan(int amount, int age) { if (amount <= 1000) { if (age >= 18) return true; else return false; } else if (amount > 2000) { if (age >= 25) return true; else return false; } else // 1000 < amount <= 2000 { if (age >= 21) return true; else return false; } else return false; //should never happen } |
This way also works, but looks totally different.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
int age_limits[3]; int low_amount_boundary, high_amount_boundary; void Initialize(void) { age_limits[0] = 18; age_limits[1] = 21; age_limits[2] = 25; low_amount_boundary = 1000; high_amount_boundary = 2000; } bool IsEligibleForLoan(int amount, int age) { int index = 1; if (amount <= low_amount_boundary) index = 0; else if (amount > high_amount_boundary) index = 2; if (age >= age_limits[index]) return true; return false; } |
The number of ways this can be done is endless. The first method “hard codes” all of the definitional parameters needed for comparison. This can be somewhat opaque and hard to maintain and update. The second method defines all the parameters as variables that can be redefined on the fly, or initialized from a file, a database, or some other source. The latter is easier to maintain and is generally preferred. It is extremely important to maintain good documentation, including in the code itself. I’ve omitted most comments for clarity, but I would definitely include a lot in production code. I would also include references to the governing documents, RTM item index values, and so on to maintain tight connections between all of the sources, trackers, documents, and implementations.
In order to understand these, you’d have to know a reasonable amount about programming, and failing that you should know how to define tests that exercise every relevant case. For example, you would want to define tests that not only supplied inputs in the middle to each range, but also supplied inputs on the boundaries of each range, so you could fully ensure the greater-than-OR-equal-to or just greater-than logic tests work exactly the way you and your customers intend. Setting the requirements for these situations may require understand of organizational procedures and preferences, industry practices, competitive considerations, risk histories and profiles, and governing regulations and statutes. None of these considerations are trivial.
You will also want to work with your implementers and testers to ensure they test for invalid, nonsensical, inconsistent, or missing inputs. It’s up to the analysts and managers to be aware of what it takes to make systems as robust, flexible, understandable, and maintainable as possible. Some programmers may not want to do these things, but the good and conscientious ones will clamor to inject the widest variety of their concerns and experiences into the process. As such, it’s important to foster good relationships between all participants in the working process and have them contribute to as many engagement phases as possible.
Finally, data comes in many forms and is used and integrated into organizations’ working processes in many ways. I discuss some of them here and here, and visually suggest some in the figure below. Some of this data is used for other purposes and doesn’t directly drive decisions, and I would not assert that one kind is more important than another. In the end, it all drives decisions and it is all important to get right.