
At yesterday’s DC PHP Developer’s Community Meetup Andrew Cassell gave a really nice presentation on Domain-Driven Design. He described the major books in the field, some of the main movers and history, and what the idea is all about.
In a nutshell, it says to understand your customers’ problems in their language, talk to them in their language, and discuss your proposed and executed solutions in their language. If you’re sensing a pattern here then you’re onto something. You are supposed to be the expert in all the computer twiddlage that you do, but your customers are not, nor generally should they be. They are the experts in all the domain-specific twiddlage that they do, and you need to respect that. Then you need to learn it. You don’t have to learn it to the level that they know it, but you have to learn enough about what they’re doing, and how they describe it, to be able to give them the functionality they need.
As Andy described, programmers tend to start thinking about data structures and UI screens as soon as they start to get some input (i.e., as soon as they start listening to the customer describe what it is they do). That’s not a bad thing, it’s a reflection of their passion and expertise. But any passion needs to be controlled, and rushing to cook up a solution before you truly understand the problem is a “one-way ticket to Palookaville.”
There’s more to it, of course, and the talk covered a lot of the tactical considerations like isolating sections of software that represent different areas of business functions so they communicate using messages rather than a closer type of coupling. Also described was how statements should be streamlined and clarified so the code itself clearly expresses business logic. Doing this ensures that elements within the computing system are always in a valid state and thus don’t need to be continuously parsed and error-checked. If done correctly — and this has always been a feeling of mine — once you understand the customer’s problem domain and have mapped out their process in sufficient detail, your code practically writes itself.
I listened to the talk with great enthusiasm because I feel I’ve essentially been doing this for my whole career. I know that the method is extremely powerful and it’s helped me write a lot of amazing software, but I haven’t felt like I’ve ever gotten anybody to understand it (this is actually the reason I created this website in the first place). People look at my resume and don’t see the common thread that holds the whole thing together. They see a bunch of different jobs, industries, and tools, many of them older, and don’t think any of it applies to them.
I cannot tell you how frustrating this has been.
Each person has their own history influenced by different sets of people, places, and events, and they each create a unique synthesis because of it. I got my degree in mechanical engineering but also took a heavy dose of computing courses (it was Carnegie Mellon after all…), so it was natural that I would try to focus my computing skills on the problems I encountered working in the paper and nuclear industries. In particular, I was a process engineer who studied, designed, and improved fluid systems where a series of pipes moved liquids (and other materials) from one machine or process to another. These things were all described by drawings like those shown here.
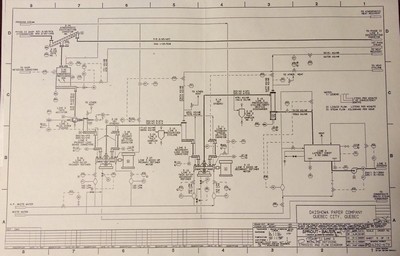
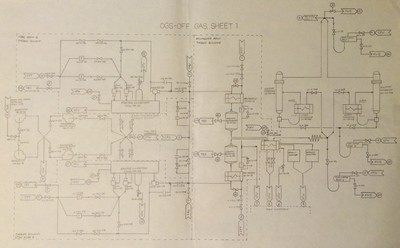
Analyzing these systems required having a map of what went where and a description of what happened in each component of the system. There were inputs, outputs, volumes, compositions, masses, flows, volumes, compositions, temperatures, energies, surface areas, variations, energy transfers, elevation changes, geometries, and transformations at every step of the process that had to be described using language appropriate to that domain (which in these cases included thermodynamics, fluid mechanics, differential equations, knowledge of making wood pulp, chemistry, radiation, failure modes, connections, and the steam cycle, many different kinds of process equipment, and other things). I first got used to working with fluid and piping systems in the paper industry but mostly did ad hoc analysis and designed a few of my own tools. When I moved to the nuclear industry it was to build full scope operator training simulators, which meant hooking complete reproductions of all the control room hardware to first principles computer models of all the fluid and electrical systems in a given nuclear power plant.
Such an undertaking requires a deep level of understanding and a huge organizational effort to get everything in order, properly labeled and interfaced, built, documented, tested, shipped, installed, verified, and accepted. In order to simulate something you need descriptions of every facet of the system and its behavior that has a material effect on its operation. In software terms this means you have to define every variable, data structure, calculation, transformation, and transfer in the system. You have to define them, name them, determine initial values for them and determine acceptable ranges of values, and test them.
If all of this didn’t happen, and with sufficient accuracy, then the thing simply wouldn’t work.
After working on projects like this I found it to be a really easy transition of doing business process reengineering using FileNet document imaging systems. In these projects the goal was to map out a company’s business processes, and then write software that allowed users to view scanned images of large volumes of paper documents in the course of their collating and evaluation work instead of the physical documents themselves. Big companies like banks, credit card processors, and insurance companies were practically deluged with paper documents back in the day but I worked with teams of consultants who added a scanning and indexing step at the front of a company’s process, and then automated the process to remove all subsequent physical handling of the documents. The combination of eliminating physical handling steps and streamlining evaluation processes through automation support reduced system costs by up to thirty percent.
We figured out what the customers needed by having them walk us through their process, which we then documented, mapped, and quantified. This defined the As-Is state of their process. We then identified the process that would be eliminated or streamlined through automation, determined the overhead, requirements, and costs of the new scanning step, and documented the configuration, costs, and requirements for the new system. This defined the To-Be state. For a disability underwriting process the domain knowledge included document indices, names, addresses, companies, medical records, risk profiles, scoring systems, sorting/scoring/collating methods, and determinations of feasibility and costs. In order to build such a system we had to talk to executives and workers in every one of the company’s operations. We never talked to the customer about the behind-the-scenes geekery that we loved as programmers, we only talked about, documented, an analyzed things in the language that we learned from them.
Once we did that then generating the UI screens, data structures, calculations, and summations were almost trivial to implement. I’ve since done the same things in other jobs and industries, as detailed in the common thread link above.
Were the programming tools different? Yes. Was the domain knowledge different? Sure. Were there still inputs, outputs, transformations, routings, decisions, and results?
Yup. Bingo. And that’s the point. The words change but the melody remains the same. I’ve learned a lot of things during my career, but this underlying understanding of how to work with customers to figure out what they need, in their own language, so I and my colleagues can give them the best possible solution, is my superpower, if I can be said to have such a thing.
The method for establishing and documenting a mutual understanding with the customer, and then progressively advancing through the design, implementation, testing, and acceptance of the solution is this:
- Define the Intended Use of the System: This means defining the overall goals of the proposed (new or modified) system in the business context.
- Identify Assumptions, Capabilities, Limitations, and Risks and Impacts: Identify the scope of the project or model and define what characteristics and capabilities it will and will not consider or include. Describe the risks and impacts of those choices. (added 22 June, 2017)
- Discover, Describe, Quantify, and Document the System: In simulation terms this would be described as building a Conceptual Model. This defines the development team and customer’s mutual understanding of the system that embodies the defined business need. This can describe an existing system, a new system, or a modified system.
- Identify the Sources of Data for the System: They must be mapped to the conceptual model of the system and validated for accuracy, authority, and (most importantly) obtainability.
- Define Requirements for the System: Functional requirements should be mapped to all elements of the Conceptual Model of the system, and this mapping should be comprehensive in both directions (that is, every point in both lists should be addressed). This mapping should be done using a Requirements Traceability Matrix (RTM). Functional requirements relating not to the business logic but to the computer hardware and software environment should also be documented, as well as the system’s Non-functional requirements (that describe not what the system does but how it should “be” in terms of robustness, accuracy, maintainability, modifiability, ongoing plans for modification and governance, and so on).
- Define the Design of the System: All of the different types of requirements listed above must be mapped (in both directions) to elements in the Design Specification. This should be done by extending the RTM.
- Implement the System (and Document it): This is addressed by the Implementation Plan, which is guided by a combination of Waterfall and Agile techniques appropriate to the project. All items should be mapped in both directions to the System Design using the extended RTM.
- Test the System: This process results in the Verification of the system and this documented activities should map in both directions to the Implementation and Design elements listed in the RTM, in both directions.
- Demonstrate that the System’s Outputs are Accurate and Meet the Customer’s Needs: This step is carried out through comparisons to real-world and expected results based on historical data and the judgment of Subject Matter Experts (SMEs). Note that outputs are more than just the data generated by the system, though this is the major goal of a simulation. They also include all of the functional and non-functional requirements having to do with the computing environment and the meta-operation of the system within the business context. Completing this step results in the Validation of the system.
- Accept or Reject the System: Determine whether the system is acceptable for the Intended Use in whole or in part, or not at all. Accepting the system results in its Accreditation (or Accreditation with Limitations if acceptance is only partial).
In summary, the need is defined; the details are identified; a solution is proposed, implemented and tested; and a judgment is made as to whether or not it succeeded. The artifacts of the system can be listed like this, and they should be mapped in both directions every step of the way. If all needs are identified and addressed as being acceptable, then the system cannot help but be fit for the intended use.
- Intended Use Statement
- Assumptions, Capabilities, Limitations, and Risks and Impacts (added 22 June, 2017)
- Conceptual Model
- Data Source Document
- Requirements Document (Functional and Non-Functional, including Maintenance and Governance)
- Design Document
- Implementation Plan
- Test Plan and Results (Verification)
- Evaluation of Outputs and Operation Plan and Results (Validation)
- Acceptance Plan and Evaluation (Accreditation)
The level of effort that goes into each step should vary with the scope and scale of the project. I describe a heavyweight methodology I was required to use for a high-profile system used to manage fleets of aircraft for the Navy and Marine Corps here. The nuclear power plant simulators I worked on employed a very similar process, and all of the other projects I participated in over the years scaled down from there.
As a final note I’ve often described how I always like to automate processes and develop tools. To that end I have written programs that implement business logic in a block-level form, such that the blocks can be connected together in a way that, when the properties of the blocks, connections, and processed entities are defined, the business logic is instantiated automatically. This is a form of Domain-Driven Design in that the components of the computing system (the blocks, connections, controllers, entities, and so on) are purpose-built to represent a particular aspect of a given problem domain. Such systems exist for electrical circuits (SPICE), business process models (BPMN), Port-Of-Entry Modeling Systems (BorderWizard and related tools I worked on), and more. I’ve written tools like this to model nuclear plant fluid systems and certain classes of general purpose, discrete-event systems.
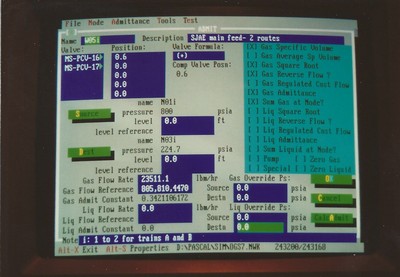
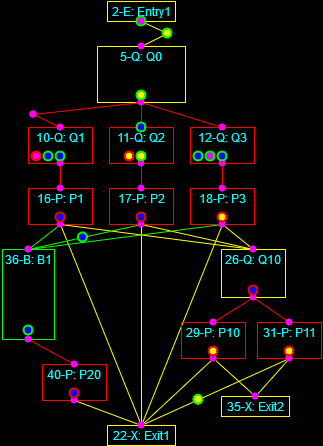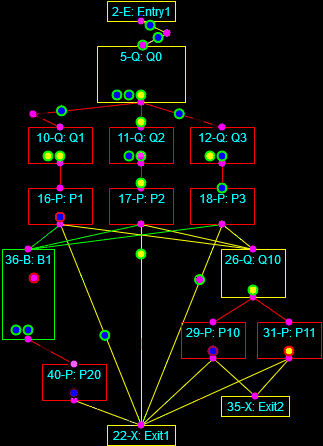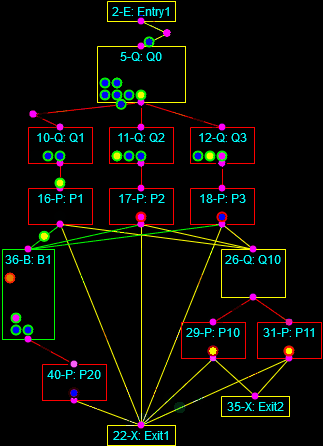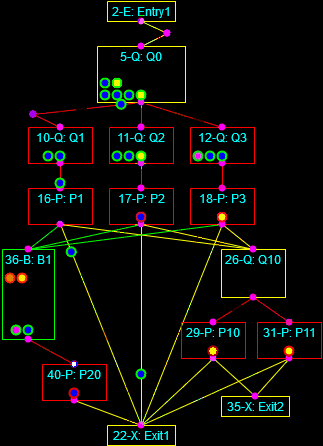
The discrete-event simulation framework I’m building is a form of visual or graphical programming (as distinguished from merely programming graphics). Here is an interesting discussion on the subject. It appears that visual paradigms work better at the level of business logic in a specific domain rather than trying to displace the low-level constructs of conventional languages.