
Continuing yesterday’s investigations I did some experiments with defining and instantiating a few objects to see how JavaScript allocates memory for them. I used the memory inspector built into Firefox to track memory and object usage as closely as possible. It’s possible that JavaScript implementations will differ in details across implementations in different browsers but I think I got a reasonable feel for what the language mechanism is doing behind the scenes.
Language and framework implementations often try to balance optimization for speed and memory usage. If a mechanism optimized for memory it might allocate heap memory for items based on their known size exactly. If the mechanism wanted to expand the size of that item dynamically it might allocate the exact space needed for a new, larger item, copy the original information over to the new item, and then fill the new memory location at the end of the new item. (“HDR” in the first element refers to the overhead the implementation stores with items that are objects. This consumes quite a few bytes.)
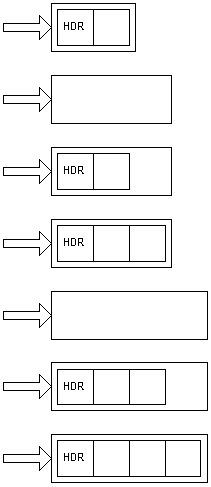
If a mechanism wanted to optimize for speed it might allocate a large area of memory and then let an item expand within that area as needed. If a mechanism wanted to balance speed and memory usage then it will allocate an initial slug of memory that allows for some growth by an item, and will go through the process of expanding the item over time as it becomes necessary. The designers of the mechanism will balance the needs of flexibility and optimization on various resources.
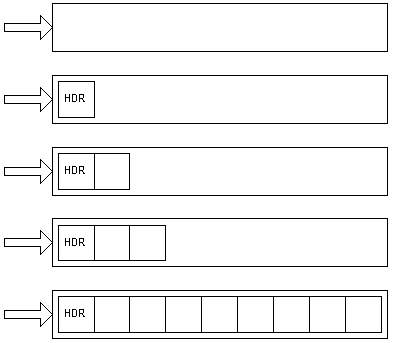

I experimented with some objects I already had but then tried creating a test object that would illuminate the exact behaviors I was curious about. What I found was interesting.
It turns out that even if the mechanism “knows” how much memory needs to be allocated it still builds items in memory so in an incremental fashion. The initial allocation of memory for the objects I was working with was 224 bytes. That happened when I declared an object with only a single numeric member. I then kept adding one number at a time until the inspector showed a larger increment. The initial allocation stayed at 224 bytes until it finally jumped to 288. Subsequent increments happened at 352, 480, 736, 1248, 2272, 4320, and 8416 bytes. If you subtract 224 from each of those values you get powers of two, or 64, 128, 256, 512, 1024, 2048, 4096, and 8192. I don’t know if the pattern keeps doubling after that. In any case it looks like an initial allocation is made and then additional space is added as increasingly larger chunks of memory. I can’t say what form the memory allocation takes, either, whether it creates the new memory, copies the old stuff over, then deallocates the old stuff, or whether it simply daisy chains new slugs of memory. Given what I know about JavaScript the latter seems entirely possible. You can never count on things being allocated contiguously in memory, as I learned from working with multidimensional arrays. I also wonder what this means for the storage of variables that would span a gap between incrementally allocated slugs of memory. For example, if there are four bytes left in the current allocation and the object is to be expanded to hold an eight byte number, would the mechanism allocate four bytes at the end of the extant memory block and the first four bytes of the new one, or would it leave the four bytes at the end of the initial block unfilled in favor of taking the first eight contiguous bytes in the new increment of memory. This brings up some other questions. Does the mechanism pack different types of data items tightly or on 2-, 4-, or 8-byte boundaries? The latter option would answer the last question conclusively; there’s a lot to know.
Why does the allocation mechanism do this? I’m guessing it’s because the definitions of objects are so flexible the mechanism never actually knows what it’s going to need, so it always builds everything on the fly without regard for what some crazed software engineer might be trying to throw at it.
Once I understood this process I started digging into the question I really wanted to answer, which is how the declaration of member functions affects the allocation of memory for objects. Here I needed to instantiate not one object but several, to get further insight into what was happening. I didn’t trace into the initialization of the objects but only recorded the memory devoted to objects (and the count of objects) as each new statement was executed to do the instantiation. The test object included 26 number values (cleverly named this.a through this.z) which would be expected to consume 208 bytes of memory (at eight bytes per number). Allocating the first object consumed 352 bytes while subsequent instantiations each consumed 272 bytes. This suggests that the internal overhead for each object is 64 bytes and the global overhead for a type of object is an additional 80 bytes.
Next I declared 26 short functions that return the value of each of the number values. If I declared all of the methods inside the closure the memory consumed was 736 byes for the first instantiation and 656 for all allocations thereafter. If I declared all of the methods as external prototypes then the instantiation for all objects, including the first one, was only 272 bytes. That suggests to me that declaring methods as external prototypes does, indeed, reduce the memory consumption of allocated objects.
I got exactly the same results when I increased the amount of code in each of the methods, so the code management overhead appears to be independent of the size of the associated code. It’s possible that there’s a threshold effect with code just like I described for memory (i.e., if I made the code even bigger it may require more memory for each object), but that’s beyond my current need and desire to investigate.
What does this mean for the ongoing discrete-event simulation project? It means that I want to migrate the methods out of the various object constructor closures whenever possible. This gets tricky when the constructors include code which has to run as part of setting up the object (beyond simply copying parameter values to internal member values) but isn’t a huge problem. I’m also thinking that I might not even bother for the component objects that make up a simulation environment. There are usually going to be fewer components that there will be entities getting processed. Entities (can) come and go at a furious pace and it’s more important to save that memory if possible. I’ve worked with models that process multiple tens of thousands of entities and that were constrained by the host machine’s resources so the memory consumption can definitely add up.
The current project’s entity object is fairly simple, by design (remember that we chose to build the intelligence into the environment components and not the entities — so far), so it will be a simple matter to externalize most or all of its methods. We can also dispense with most of the setters and getters, which seem to be more trouble than they’re worth in JavaScript. It doesn’t feel like “good practice” but it seems right from the balance of engineering considerations.