
Today I began implementing the capability of handling different types of entities. The two main aspects of this problem are how to assign properties to an entity and how those properties affect how an entity is processed by different parts of the system.
Addressing the first aspect, I originally defined a property of entityType that was supplied as a parameter to the entity’s constructor, and that value was set to zero for all entities and thereafter ignored. This is an example of defining a custom property for each type of characteristic. This is a good option if you are hard-coding a simulation for a specific application. Another option would be to define a base class and then attach custom properties through inheritance. Still another option, which I am implementing today, involves creating a general structure to define an arbitrary number of properties for each entity. I’m doing this with the idea of creating the most abstract and general type of base framework. In this we are trading away some speed and clarity for generalizability.
I first define a global data structure that describes what all the characteristics are and what values each characteristic can take on. Conceptually it looks like this:
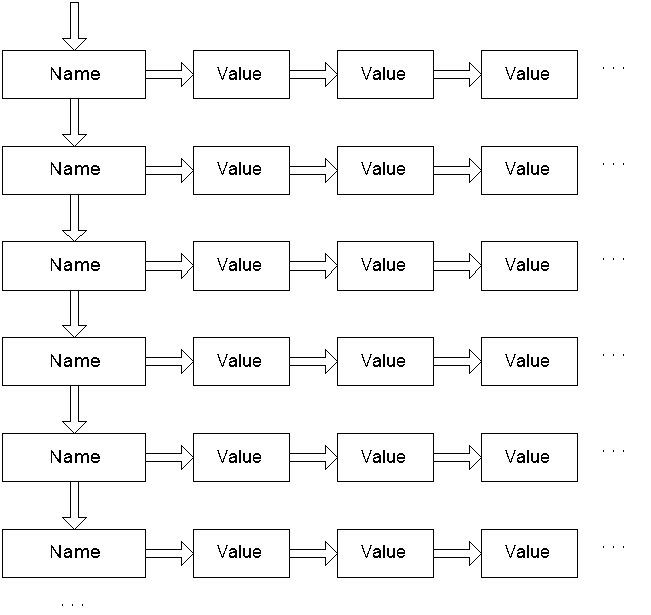
This can be implemented as a two-dimensional linked list, a two dimensional array, a list of arrays, or whatever, so the depiction is rather general. In this example, and since we’re using JavaScript, we’ll use an array of arrays, where the first element of each sub-array is the name of the property (e.g., color) and the subsequent elements are the possible values of that property (e.g., “orange,” “ecru,” “chartreuse“).
This entire structure should be defined before any entity is defined. When each entity is defined, it includes a property called propertyList, which is a single-dimensioned list (array) of values for each possible characteristic. We could allow multiple values per characteristic but let’s just keep it simple, OK?
This mechanism is a bit kludgy and slow since it will often involve the use of strings, the comparison of which adds a certain amount of overhead. There are many ways to improve on the compactness and speed of the operations we’ll add (enumerated types, bitwise mapping, and so on), but this will keep things very clear and require the least amount of custom coding.
Here’s the code for the global data structure and the passive entity type. The data structure defining properties and values is defined first so that entities, when they are created, can be set up to store values for each possible property. The setProperty method is used to define an entity’s properties when it’s created and the getProperty method is used to determine the entity’s properties when it’s being processed.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 |
//***************************************************************************** //*** Entity definitions //***************************************************************************** //global entity properties entityProperties = []; numEntityProperties = 0; function defineEntityProperty(propertyName,property) { var i = 0; while ((i < numEntityProperties) && (propertyName != entityProperties[i][0])) { i++; } if (i < numEntityProperties) { //propertyName already in list, add property entityProperties[i].push(property); } else { var p = []; p[0] = propertyName; p[1] = property; entityProperties.push(p); numEntityProperties++; } } //entity item passive //stores minimal state information, does nothing on its won function EntityPassive(entityType) { this.entityID = getNewEntityID(); this.entryTime = globalSimClock; this.entityType = entityType; var p = []; for (var i=0; i<numEntityProperties; i++) { p[i] = 0; } this.propertyList = p; this.entityColor = "#FFFFFF"; //default color, should set this based on its properties this.localEntryTime = 0.0; this.componentGroup = ""; this.componentGroupEntryTime = 0.0; this.xLocation = 0.0; this.yLocation = 0.0; this.permissionToMove = false; this.forwardAttemptTime = Infinity; this.getEntityID = function() { return this.entityID; }; this.getEntryTime = function() { return this.entryTime; }; this.setLocalEntryTime = function() { this.localEntryTime = globalSimClock; }; this.getLocalEntryTime = function() { return this.localEntryTime; }; this.setComponentGroup = function(componentGroup) { this.componentGroup = componentGroup; }; this.getComponentGroup = function() { return this.componentGroup; }; this.setComponentGroupEntryTime = function(componentGroupEntryTime) { this.componentGroupEntryTime = componentGroupEntryTime; }; this.getComponentGroupEntryTime = function() { return this.componentGroupEntryTime; }; this.getEntityType = function() { return this.entityType; }; this.setPropertyValue = function(propertyName,propertyValue) { var i = 0; while ((i < numEntityProperties) && (propertyName != entityProperties[i][0])) { i++; } if (i < numEntityProperties) { this.propertyList[i] = propertyValue; } else { alert("Trying to set out of range entity property"); } }; this.getPropertyValue = function(propertyName) { var i = 0; while ((i < numEntityProperties) && (propertyName != entityProperties[i][0])) { i++; } if (i < numEntityProperties) { return this.propertyList[i]; } else { alert("Trying to get out of range entity property"); } }; this.setLocation = function(xloc, yloc) { this.xLocation = xloc; this.yLocation = yloc; }; this.getLocation = function() { return {x: this.xLocation, y: this.yLocation}; }; this.setPermission = function(permission) { this.permissionToMove = permission; }; this.getPermission = function() { return this.permissionToMove; }; this.getForwardAttemptTime = function() { return this.forwardAttemptTime; }; this.setForwardAttemptTime = function(forwardAttemptTime) { this.forwardAttemptTime = forwardAttemptTime; }; this.setEntityColor = function(color) { this.entityColor = color; }; this.getEntityColor = function() { return this.entityColor; }; this.drawEntity = function() { //(entityColor) { //in this case x and y are absolute screen coords drawNode(this.xLocation, this.yLocation, 5, this.entityColor); }; } //EntityPassive |
Now we come to the other main aspect of this problem, which is how an entity’s characteristics affect how it is processed. In practice, in this kind of model, an entity’s type can determine its processing time (within any given component) and diversion percentage (the chance of going to each connected, downstream component when it gets forwarded from its current component). If we’re simulating a tollbooth we might choose a process time of 45 seconds for vehicles paying by cash but only 10 seconds for vehicles with automated transponders (e.g., E-ZPass). Travelers entering a country at a port of entry might be referred for secondary processing at random two percent of the time if they are a citizen of that country of ten percent of the time if they are a non-citizen. The diversion rate for citizens of watchlisted countries might be referred at an even higher rate.
Let’s tackle processing times first, since that’s just a single value for now. Processing times at different Process components may be dependent on different properties. I’ve modeled 40 or 50 land border crossings and know that primary processing time might be affected by citizenship, conveyance type (i.e., car, truck, bus, pedestrian), and membership in pre-clearance programs while the time it takes to pay tolls will depend on the method of payment. Therefore, a different method of identifying types has to be determined for each type of Process component and the value of the process time has to be specified for relevant combination of types. We’ll create dedicated functions to define synthetic type indices that will be used to determine the process time to use.
Let’s define some properties. The first lines define the properties and values that are possible while the function is called to assign values to each entity’s properties when it’s created. Notice also that the function assigns a color value to each entity based on its residency type (blue, purple, and yellow) and modifies it (light or darker) based on its processing speed. The display code has been updated so that the entities are represented as the same 5-pixel radius, red or green circle based on movement permissions we’ve had until now, but with a 3-pixel radius disk superimposed to show the type of entity. (The 3D entities haven’t yet been updated to incorporate this information.) Using lighter and darker colors is not the clearest way to differentiate easily between fast and slow entities but it demonstrates the idea. I’ve used more explicit text and graphic indicators to represent types and statuses in other simulations I’ve written, and the BorderWizard family of simulation tools I worked on used several graphical queues to represent different property values. Conveyance types (car, truck, bus, pedestrian) were represented by different shapes, residency type by different vehicle colors, toll type by hood color, and commercial vehicle type by trailer color. We’re keeping things simple for this project but the possibilities are endless.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
defineEntityProperty("Process Speed","Fast"); defineEntityProperty("Process Speed","Slow"); defineEntityProperty("Residency","Citizen"); defineEntityProperty("Residency","LPR"); defineEntityProperty("Residency","Visitor"); function assignEntityTypes(entity) { //we have to create some custom code here var result = Math.random(); var speed; if (result <= 0.3) { entity.setPropertyValue("Process Speed","Fast"); speed = 1; } else if (result <= 1.0) { entity.setPropertyValue("Process Speed","Slow"); speed = 2; } //skip testing other possibilities result = Math.random(); if (result < 0.65) { entity.setPropertyValue("Residency","Citizen"); if (speed = 1) { entity.setEntityColor("#0000FF"); } else { entity.setEntityColor("#000088"); } } else if (result < 0.75) { entity.setPropertyValue("Residency","LPR"); if (speed = 1) { entity.setEntityColor("#FF00FF"); } else { entity.setEntityColor("#880088"); } } else if (result < 1.0) { entity.setPropertyValue("Residency","Visitor"); if (speed = 1) { entity.setEntityColor("#FFFF00"); } else { entity.setEntityColor("#888800"); } } } |
Now we’ll create functions that generate indices based on the values of the properties. We’ll have all the entities with an E-ZPass-like credential get processed in a one time, visitors without a fast credential get processed in a different time, and citizens and legal permanent residents (LPRs) without fast credentials get still a different processing time. A similar function for diversion percentages generates indices strictly based on residency type. These can be custom-generated for each type of component on a case-by-case basis.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
function entityProcessTimeIndex(entity) { var index; if (entity.getPropertyValue("Process Speed") == "Fast") { index = 0; } else if (entity.getPropertyValue("Residency") == "Visitor") { index = 1; } else { index = 2; } return index; } function entityDiversionPercentIndex(entity) { var index; if (entity.getPropertyValue("Residency") == "Citizen") { index = 0; } else if (entity.getPropertyValue("Residency") == "LPR") { index = 1; } else if (entity.getPropertyValue("Residency") == "Visitor") { index = 2; } return index; } |
SO how does all this information get used? First we’ll expand the definition of process times and routing tables we pass to the components as they’re defined. Notice that we don’t assign special traverse times to the Queue component because that is about how long it takes to traverse a queue (and this value might be zero) and doesn’t necessarily have anything to do with the type of entity. For the routing table we’re saying that citizens don’t get diverted to secondary very often, LPRs get diverted slightly more often, and visitors get diverted quite often. (These percentages are only chosen to illustrate the effects.)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
var routingTableP123 = [[0.92, 1.0],[0.85,1.0],[0.548,1.0]]; //citizen, LPR, visitor / exit, secondary var processTimeP123 = [10.0,20.8,13.0]; //fast, slow visitor, slow citizen or LPR var process1 = new ProcessComponent(2.0, processTimeP123, 1, routingTableP123); process1.defineDataGroup(5, 477, 80, globalNeutralColor, globalValueColor, globalLabelColor); process1.setExclusive(true); process1.setRoutingMethod(3); //1 single connection, 2 distribution logic, 3 model logic process1.setComponentName("P1"); process1.setComponentGroup("Primary"); ... var routingTableQ10 = [[1.0],[1.0],[1.0]]; //not actually needed since routingMethod is 2 here var queue10 = new QueueComponent(2.0, 3.0, Infinity, routingTableQ10); queue10.defineDataGroup(230, 353, 80, globalNeutralColor, globalValueColor, globalLabelColor); queue10.setRoutingMethod(2); //1 single connection, 2 distribution logic, 3 model logic queue10.setExclusive(false); queue10.setComponentName("Q10"); queue10.setComponentGroup("Secondary"); |
Then we’ll have to change how the variables are accessed within the components themselves. Here’s how process time is handled within Process components; we simply use the process time element indicated by the array index we generate based on the entity’s property values, in the second and third lines from the bottom.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
this.receiveEntity = function(entity) { //ProcessComponent //receive the entity entity.setLocalEntryTime(); //record time entity entered process if (entity.getComponentGroup() != this.componentGroup) { entity.setComponentGroup(this.componentGroup); entity.setComponentGroupEntryTime(globalSimClock); recordGroupStatsSystemEntry(this.componentGroup); } entity.setForwardAttemptTime(Infinity); entity.setPermission(false); //entity has reached end of related components group, permission no longer matters this.entityQueue.unshift(entity); this.countInQueue++; this.countInProcess++; //TODO: handle if process time is zero? this.isOpen(); //display what was done this.entryTime = globalSimClock; this.entryEntityID = entity.entityID; this.activity = "receive entity"; //set timer to clear the display after a bit this.endEntryDisplayTime = globalSimClock + this.displayDelay; this.endAllDisplayTime = this.endEntryDisplayTime; advance(this.displayDelay, this, "clearEntryDisplay"); //set timer for the process duration var pTime = this.processTime[entityProcessTimeIndex(entity)]; advance(pTime, this, "processComplete"); displayProgressText("Process comp. " + this.componentID + " receives entity: " + this.entryEntityID + " at time " + globalSimClock.toFixed(6)); }; |
Diversion percentages work the same way except they apply to all components except Arrivals, Paths, and Exits. It only matters when we’re model logic routing (option 3) and it only has an effect when an entity is available to be forwarded. Other than that we’ve simply added an extra layer of indirection. (The relevant code starts on line 37.)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 |
this.forwardEntity = function(destIndex) { //ProcessComponent if (typeof destIndex === "undefined") {destIndex = -1;} var dest = -1; if (destIndex >= 0) { //pull request from a specific downstream component, must send entity there if (this.routingMethod == 1) { //single connection, nothing to do dest = 0; } else if (this.routingMethod == 2) { //distribution, send to any request dest = 0; while ((this.nextComponentIDList[dest] != destIndex) && (dest < this.nextComponentCount)) { //second test should not be needed, loop can't fail to return valid result dest++; } } else if (this.routingMethod == 3) { //model routing logic, TODO: don't forward if not desired destination dest = 0; while ((this.nextComponentIDList[dest] != destIndex) && (dest < this.nextComponentCount)) { //second test should not be needed, loop can't fail to return valid result dest++; } } dummy2 = 0; } else { if (this.routingMethod == 1) { //single connection if (this.nextComponentList[0].isOpen()) { dest = 0; } } else if (this.routingMethod == 2) { //distribution var nextIndex = this.nextOpen(); if (nextIndex >= 0) { dest = nextIndex; //this.nextComponentIndex = dest; } } else if (this.routingMethod == 3) { //model routing logic if (this.savedDestination >= 0) { dest = this.savedDestination; } else { dest = 0; var test = Math.random(); //new and modified code starts here //need access to entity type but can't pop it off queue here var index = this.countInQueue - 1; if (index >= 0) { index = entityDiversionPercentIndex(this.entityQueue[index]); //get head item in queue and find out what type it is } else { index = 0; //nothing in queue, following code will work but nothing will be popped and processed below } while (test > this.routingTable[index][dest]) { dest++; } //new and modified code ends here if (dest <= this.nextComponentCount) { if (!this.nextComponentList[dest].isOpen()) { dest = -1; } } else { alert("Process comp. tried to assign destination with too high of an index") } if (dest >= 0) { this.savedDestination = dest; //ensure that once destination is determined for this entity that we don't keep changing it } } } else { //0 uninitialized or anything else alert("comp. " + this.componentID + " incorrect routing method: " + this.routingMethod); } } if (dest >= 0) { if (this.countInQueue > this.countInProcess) { var entity = this.entityQueue.pop(); //TODO-: are we testing to ensure the next entity is really available if (entity) { //TODO-: since we've tested above this should not be necessary //calculate how long item was in process this.exitResidenceTime = globalSimClock - entity.getLocalEntryTime(); this.exitTime = globalSimClock; this.exitEntityID = entity.entityID; this.activity = "forward entity"; this.endExitDisplayTime = globalSimClock + this.displayDelay; this.endAllDisplayTime = this.endExitDisplayTime; advance(this.displayDelay, this, "clearExitDisplay"); displayProgressText("Process comp. " + this.componentID + " forwards entity: " + this.exitEntityID + " at time " + globalSimClock.toFixed(6)); this.countInQueue--; //should be open now if (this.exclusive) { displayProgressText("Process comp. " + this.componentID + " calls pull from previous at time " + globalSimClock.toFixed(6)); if (!this.openStatus) { this.pullFromPrevious(); //TODO: call this with a modest (~1 sec) delay to account for reaction time? //may or may not successfully get an entity but should always be called } } this.isOpen(); this.nextComponentIndex = dest; this.savedDestination = -1; //clear old choice when entity successfully forwarded this.nextComponentList[dest].receiveEntity(entity); //record stats recordGroupStats(this.componentGroup, entity.getComponentGroupEntryTime()); } } } }; |
So that’s all there is to it! Well, OK, it’s easy enough but spread around quite a lot. This first pass at adding this functionality works, as you can see by running the model, but we still need to streamline this process if possible and add some validation. For example, we should ensure that the size of each array and sub-array matches the number of possibilities that actually exist. We ultimately want to assign these values in the clearest way possible but there is an unavoidable level of complexity that the programmer will have to deal with. If you have any suggestions for ways to simplify any of this (before I think of some), then by all means let me know. We also need to update the reporting capability to capture statistics relevant to the new subtypes we’ve defined, and we need to find a way to add type indicators to the entities in the 3D representation.