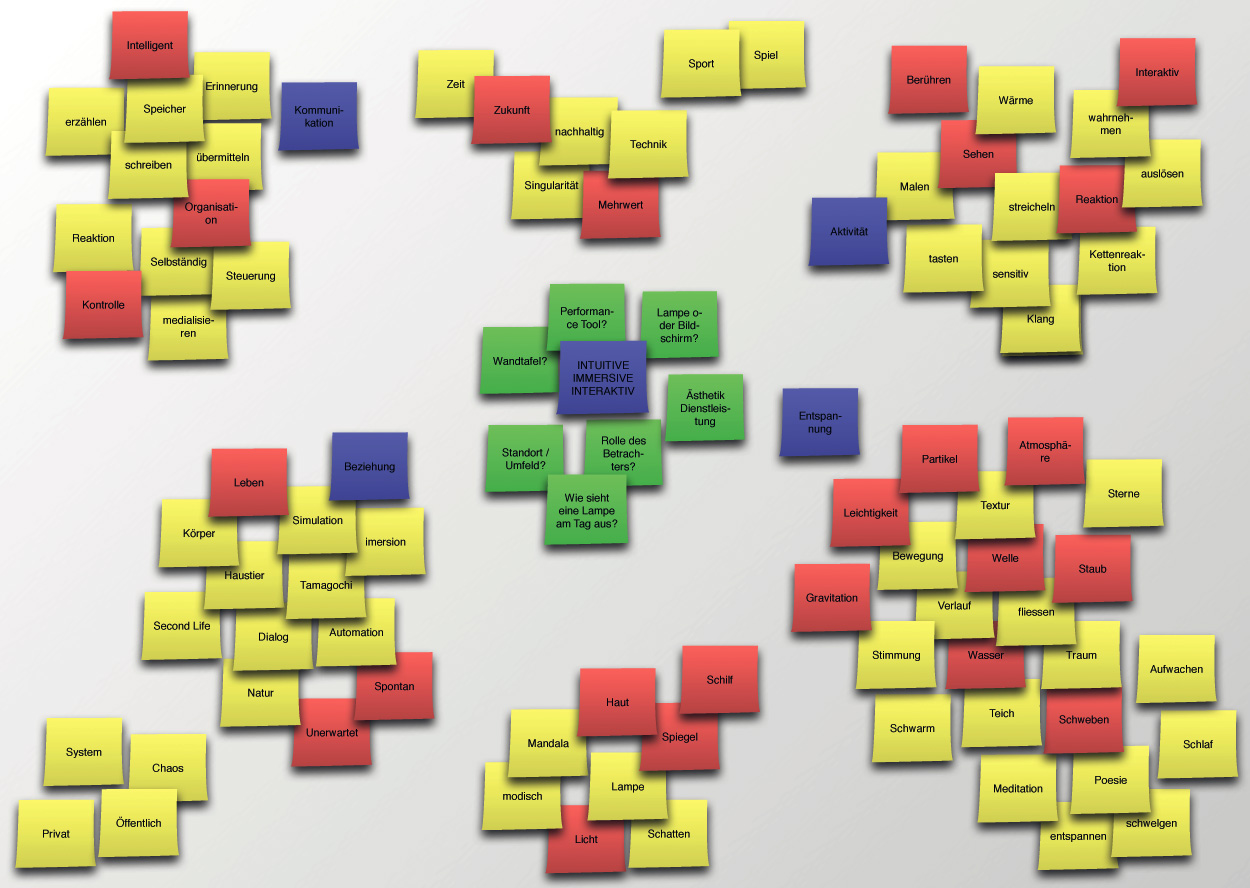
The definition given in the BABOK is, “A user story represents a small, concise statement of functionality or quality needed to deliver value to a specific stakeholder.” This is a very general definition and is potentially different from a task assignment. These are usually employed during the requirements phase, whereas tasks may be assigned in any phase. I discuss a way to think about these activities and how to track them here.
A classic user story is often written in the following form:
As a role , I would like to take some action so I can achieve some result .
This format can be thought of in terms of who, what, and why. “Given… when… then…” is another possible format. I opine that requirements especially, and tasks more generally, should be written in any format that yields the correct results. As long as the person or persons assigned the requirement or task accomplish the desired thing, the expression is “correct.” I share this because some people may demand that (especially) requirements must be written in a particular way, and I think such demands miss the point.
So what are we trying to communicate in these stories?
- Stakeholder Needs: The stories attempt to provide chunks of future capability that serve stakeholder needs.
- Solution Needs: Some stakeholder needs cannot be fulfilled without supporting capabilities that may not have been identified by the stakeholders. These often take the form of technical and other indirect prerequisites.
- Prioritization: This describes the order in which things must be done. This can be expressed as a directly scored parameter (e.g., high, medium, low) or indirectly through processes like backlog grooming.
- Estimation: This can involve costs in time and various resources and also benefits. Being mindful of both supports cost-benefit analyses.
- Solution Delivery Plans: Defining what is needed begins to define how it can and should be delivered.
- Definition of Ready: This is a measure of how clear and complete a story has to be before it may be assigned to be worked on.
- Definition of Done (Testing Requirements): An almost limitless variety of tests may be performed on units of delivered value. This definition says something about the tests the delivered value must pass.
- Value Delivered: This defines the value of the capability delivered. It supports a wide variety of analysis.
- Traceability (within the logical design hierarchy and across phases): Each story should relate to other ones in ways that make logical sense.
- Subsequent Analysis: Developing and prioritizing stories may help clarify existing stories and illuminate the need for new ones.
- Units of Project Management and Reporting: Organizations need to be able to manage resources (time, money, materials, labor, and environmental factors) to understand how much they can accomplish relative to what is desired.
User stories should ideally have a number of desirable attributes, as often enumerated in the acronym, “INVEST.” They should be Independent, meaning that the descriptions should lead to creating the right outcomes no matter what else is happening; Negotiable, in that a team can employ examine related trade-offs from many points of view; Valuable, so they are seen to provide provable benefits; Estimable, so the team and identify the relevant costs across all resource types; Small, so they can be worked in manageable increments; and Testable, so they can be demonstrated to meet standards defined for them by the relevant parties.
Larger stories should ultimately be broken down into smaller ones until they are of proper granularity. Some of the criteria for breaking down user stories is summarized here. They can and should be examined and broken down (or rightsized) when enough is known to conduct a proper analysis. Ideas can enter the effort at any scope and scale. Larger-scale ideas are sometimes referred to as epics. Those can be broken down into individual user stories, and those can be broken down into potentially multiple tasks.
One the one hand, calling these items user stories might be a little goofy. This indicates that the main way to describe needs for an effort is in terms of what benefits users. One the other hand, what other standard of value should there be? I think some of the confusion stems from the fact that user stories and the tasks needed to implement them, as well as the epics groups of stories may comprise, are often discussed somewhat interchangeably. As long as we are careful to define terms and otherwise be clear, this should not pose too much of a problem.